Ingest Data from Local file System to MySQL Database
Ingest Data from Local file system to MySQL Database
This tutorial will be covering an end to end use-case of loading data from a local file system to a table in MySQL. It will be using Guzzle’s ingestion activity which allows moving data from any source dataset to a target dataset applying various validations, transformations and rejections.
In this tutorial we cover#
Pre-Requisites
Load Dataset from Local File to the Guzzle Platform through its Source Section
Perform Validations and Transformations on the Dataset to check the accuracy of Data in order to mitigate any project defects
Loading or configuring the Source Dataset to a Target Dataset or Table
Applying a Failure Threshold to the Loaded Data to check the consistency and viability of the Data as a whole
Pre-Requisites#
Since we use Guzzle as our Data Engineering Workbench for movement and transformation we must ensure it is set up and configured properly. Guzzle supports both on-premise and cloud deployment.
Ensure that the file is saved in an available Source Location. This is essential as the Data will be ingested from this Local File System.
Ensure that the Target Location is available in order to prevent any errors after the Data has been Transformed and Validated.
Guzzle should be configured to support Azure Databricks and MySQL. This is essential as we will be using a MySQL Database in this tutorial. It will also help in exploiting all of Guzzle’s Features.
Load Dataset from Local File to the Guzzle Platform through its Source Section
Load Dataset from Local File to the Guzzle Platform through its Source Section#
The first step in the Ingestion Process would be to deal with the Source Section of Guzzle. Guzzle’s Source Section provides many features including specifying the file names, location of the file and the file format.
In the Datastore option choose the Dataset you would like Guzzle to work on. Ensure that the Dataset is stored in the Local File before choosing it.
Under the File Format choose the required File Type. Guzzle provides options from the delimited which is a fixed length system to multi-structured systems XML, JSON, REG-EXP.
According to your requirements you may choose to Trim Whitespaces, Introduce Headers and Infer Schema.
Guzzle also provides a feature to Sample your Data. This option can be seen in the top right corner of the Interface.

As seen above we have chosen the Delimited Format with the csv file pattern. The option to Sample Data can also be seen in the Top Right Corner.
Perform Validations and Transformations on the Dataset to check the accuracy of Data#
The next step would be to perform Validations and Transformations on the Data. This is done to mitigate any project defects and will produce the best results possible. Guzzle helps in making Data Integration a much quicker process as it Automates the Validation Process.
Enter the Name of the Column you would like to perform the Validation or Transformation on.
For transformation, you can enter the Transformation you would like to perform on the chosen Column. For Example- If the distance is in miles you can convert it to kilometers by entering distance*1.6 in the Transformation Section.
You may also choose to Validate the Data Type of the Column. In the Data Type Section choose the Data Type you would like to Validate the Column with. Also, tick the Validate Data Type box located next to it.
You may also Validate the Column to be either Unique or Nullable. Just tick the respective boxes.
In the SQL Validation you may enter a condition in order to Partition the Columns depending on whether they satisfy the given condition. You can run your validations by clicking the tick at the top of your interface.
 Here we have Validated the Columns first_name and age for their data types and entered a condition to partition the column age while validating its Nullability.
Here we have Validated the Columns first_name and age for their data types and entered a condition to partition the column age while validating its Nullability.Loading or configuring the Source Dataset to a Target Dataset or Table#
We now have to load the Source Dataset to a Target Dataset or Table. Guzzle provides many Datastores from Local Files, Delta Tables and MySQL. It allows configuring a Target Partition Scheme.
In the Datastore option choose the Target you would like to configure the Source Dataset to according to your requirement. Here we choose MySQL as we are ingesting Data into a MySQL Database.
We can now give any name to the Target in the Table Section. We can again Sample the Data through the Sample Data option given in the top right corner.

Here we have chosen MySQL as our Datastore and assigned the name customer to our Table.
Applying a Failure Threshold to the Loaded Data to check the consistency and viability of the Data as a whole#
We now move onto the Reject Section where we deal with the Data which does not pass our Validations. This helps to check the consistency and viability of the Data as a whole.
We first choose the Datastore where we like to store the Rejects which do not pass our Validations. The Datastores we can choose range from Text Files to Tables.
We may also choose to apply a Failure Threshold which is basically the maximum percentage of failed records which our dataset can have.
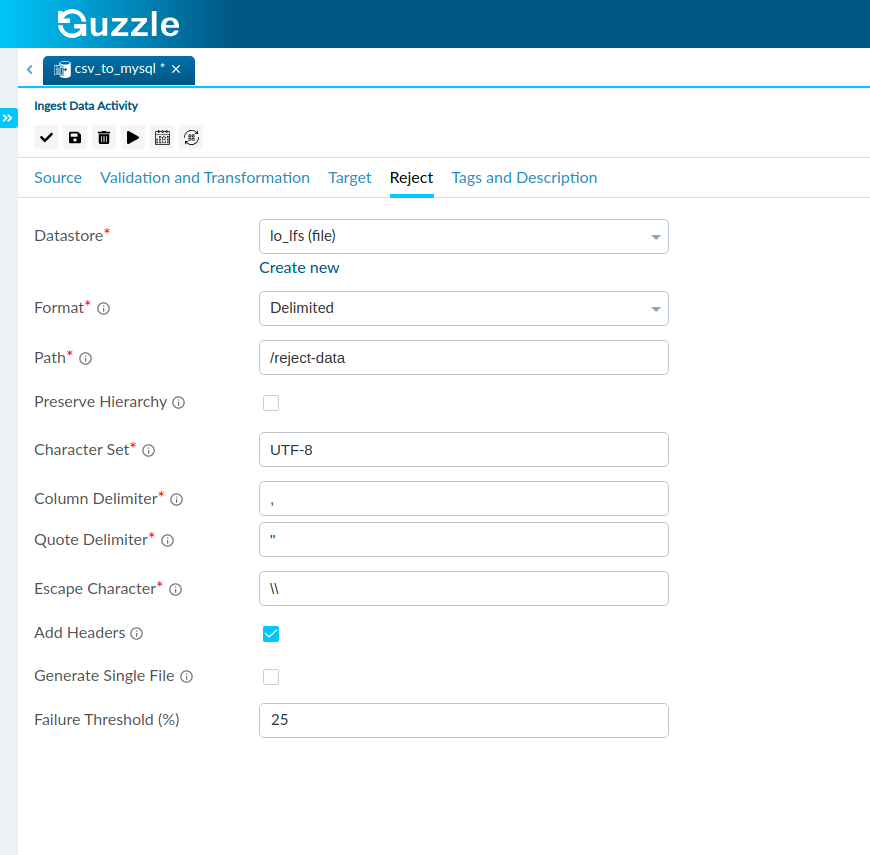
Here we store our rejects in a Local File in the Delimited Format and apply a Failure Threshold of 25%.