Azure Synapse Spark
Prerequisites#
- Below are the Azure resources which will be required when leveraging Synapse Spark in Guzzle
| Resource | Description | Steps for creating the resources | Information to retrieve (which is then used for Guzzle environment configurations and setting up Computes/data stores) |
|---|---|---|---|
| Synapse Workspace | Synapse workspace to be used for Guzzle. | Steps to create synapse workspace | Development endpoint URL |
| Synapse Spark Pool | Spark pool added in synapse workspace that will be used by Guzzle | Steps to setup synapse spark pool | - |
| App Registration | Register service principal app for Guzzle and generate secret - This app registration is being used for Authentication and hence and the steps for Authentication setup can be skipped. | App Registration steps | Client Id, Client Secret and Tenant ID (From App registration overview) |
| Blob Storage Account | Blob account used for shared storage account permission to Storage Blob Data Contributor. Select Service principal(Registered App) as Member. - You need to disable soft delete because we are using ADFS protocol to access (for databricks). - Disable Blob Storage Soft Delete | Steps to assign Storage Blob Data Contributor role to service principal | - |
| Key Vault | Key vault used to store different credentials (assumes one key vault is used to store all the credentials which are required for Guzzle environment configurations and data stores) | Assign a Key Vault access policy | - |
- This are the permissions to be granted to different AAD principals (User/groups/service principals / managed identity) on different resources (follow standard Azure document to grant permissions)
| AAD principal (User/groups/service principals / managed identity) | Resources | RBAC (permission) | Purpose |
|---|---|---|---|
| Guzzle VM system identity (or user defined identity) | Key Vault | Secret permission: Get, List, Set | Guzzle VM needs to retrieve keys from key vault and also need to save passphrase in the KV for Sync Passphrase function in for API Api Settings - Guzzle |
| Azure Service principal (App Registration) | Primary storage ADLS | Blob Contributor | The spark jobs will read and write log files/temp files in the Primary storage as part of the job run. Since the job is run using service principal (app registration), same has to be grated read write permission on primary ADLS |
| Azure Service principal (App Registration) | Synapse workspace | In Add role assignment section: - In Add role assignment section: - Role - > Synapse Admin | Guzzle will submit the jobs to Synapse workspace and run the jobs spark pool - for this it needs minimum: Synapse Admin permission. |
| Azure Service principal (App Registration) | Key Vault | Secret permission: Get, List, Set | The job which runs on spark-pool are submitted using service principal (app registration), and will need to retrieve the credential from KV for the data store |
| Azure Service principal (App Registration) | Blob Storage | Blob Reader | The job which runs on spark-pool are submitted using service principal (app registration), and will need to retrieve guzzle binaries from the shared storage ( we only need to read binaries) - The guzzle binaries are written into shared storage by Guzzle VM using account key or service principal depending on what is configured in this setup: Shared Storage - Guzzle |
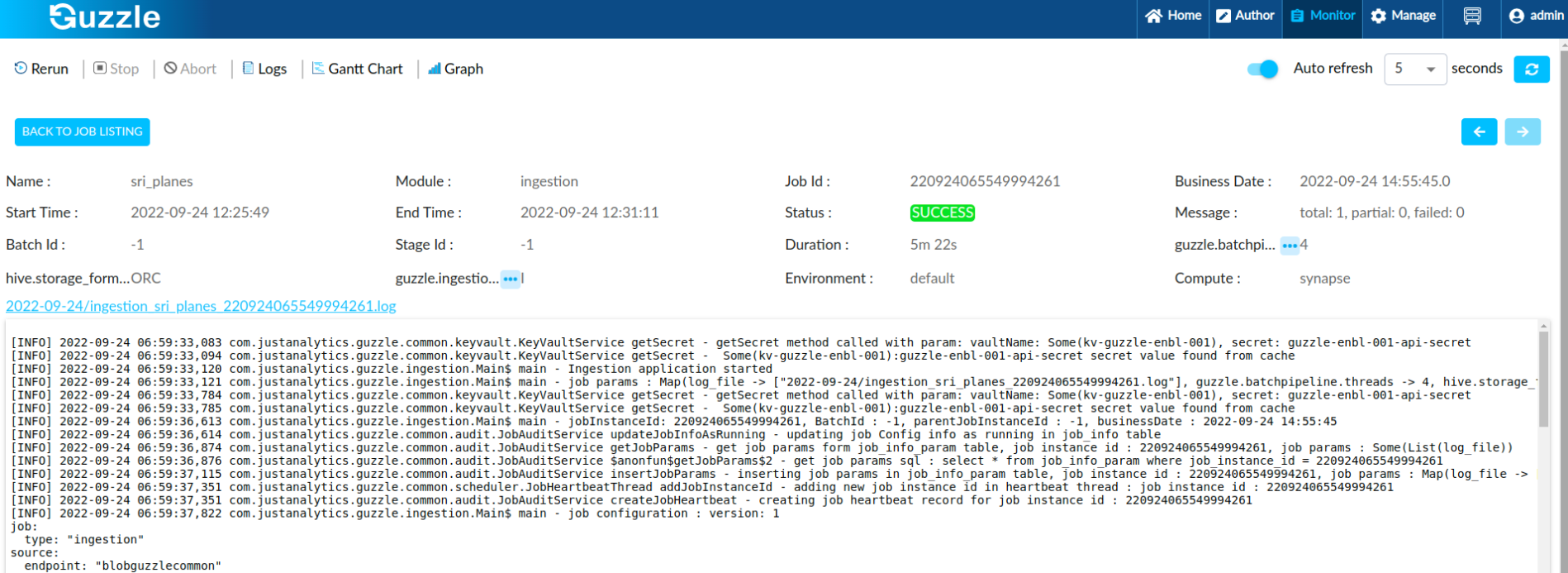
Guzzle Network Diagram for public endpoint#
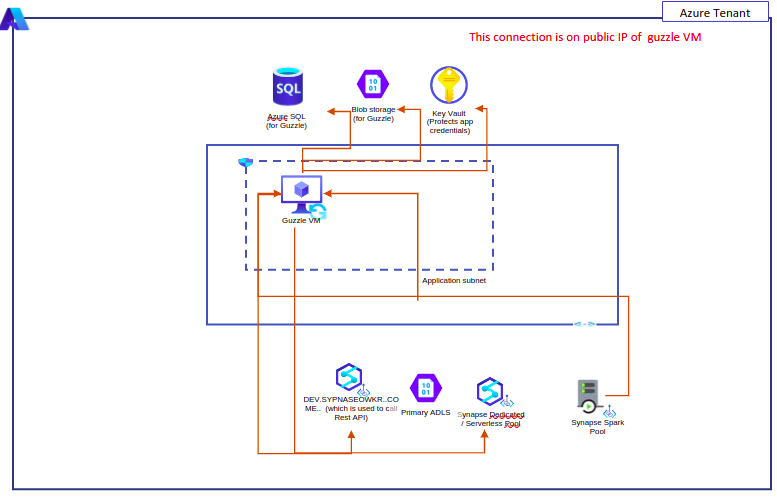
- Synapse workspace is available on public network (as per default setup) the Developer endpoint can be connected over internet. Click here for more information. All this traffic are on public end point
- The job which runs on spark-pool are submitted using service principal (app registration)
Guzzle VM Connection Table for public endpoint#
| # | Source | Target | Protocol / /port | Authentication Mechanism | Purpose of Connection | Traffic Type | Notes (latency , through put, special security) |
|---|---|---|---|---|---|---|---|
| 1 | Guzzle VM | BLOB for Guzzle | HTTPS | Managed Identity (system generated or user defined identity of Guzzle VM) | To store jars, third party library on blob for jobs on spark compute to read | Public | - |
| 2 | Guzzle VM | Azure SQL for Guzzle | HTTPS | AAD user credential / native SQL account | Read/write Guzzle audit and metadata | Public | - |
| 3 | Guzzle VM | Key Vault | HTTPS | Managed Identity (system generated or user defined identity of Guzzle VM) | Get stored secrets and keys | Public | - |
| 4 | Guzzle VM | Synapse Developer Endpoint | HTTPS | App Registration | Submit jobs to Spark Pool | Public | - |
| 5 | Spark Pool | Synapse Dedicated Pool (using Azure Synapse Native datastore) | HTTPS | App Registration which is specified in compute or Native user/password | Authentication Mechanism: - App Registration which is specified in compute or Native user/password - the external data source includes an authentication method, that's why - purpose of connection: - for Ingestion: To read and write (connector) - for processing: To run template SQL (JDBC connection) - for DQ/Recon: To read (connector) | Public | |
| 6 | Guzzle VM | Synapse Dedicated Pool (using Azure Synapse) | HTTPS | Native user/password | Processing jobs run directly from Guzzle VM against API | Public | - |
| 7 | Spark pool | Guzzle VM | HTTPS | temp API key which is part of request and decrypted using passphrase in KV | Spark job to connect to guzzle API to retrieve config | - | - |
| 8 | Spark pool | Blob storage | HTTPS | App Registration | Spark jobs to retrieve the config | - | - |
| 9 | Spark pool | Azure SQL | HTTPS | user/password or App Registration specified | to update repo tables | - | - |
| 10 | Spark pool | Primary ADLS | HTTPS | App Registration | to read/write logs | - | - |
| 11 | Spark pool | Key vault | HTTPS | App Registration | to fetch secrets from KV | - | - |
| 12 | Spark pool | Synapse Developer Endpoint | HTTPS | App Registration | it will connect to Synapse Developer end point to stop the job | - | - |
- Apart from this, there will be additional network traffic between spark pool to source and target used in the ingestion/processing job.
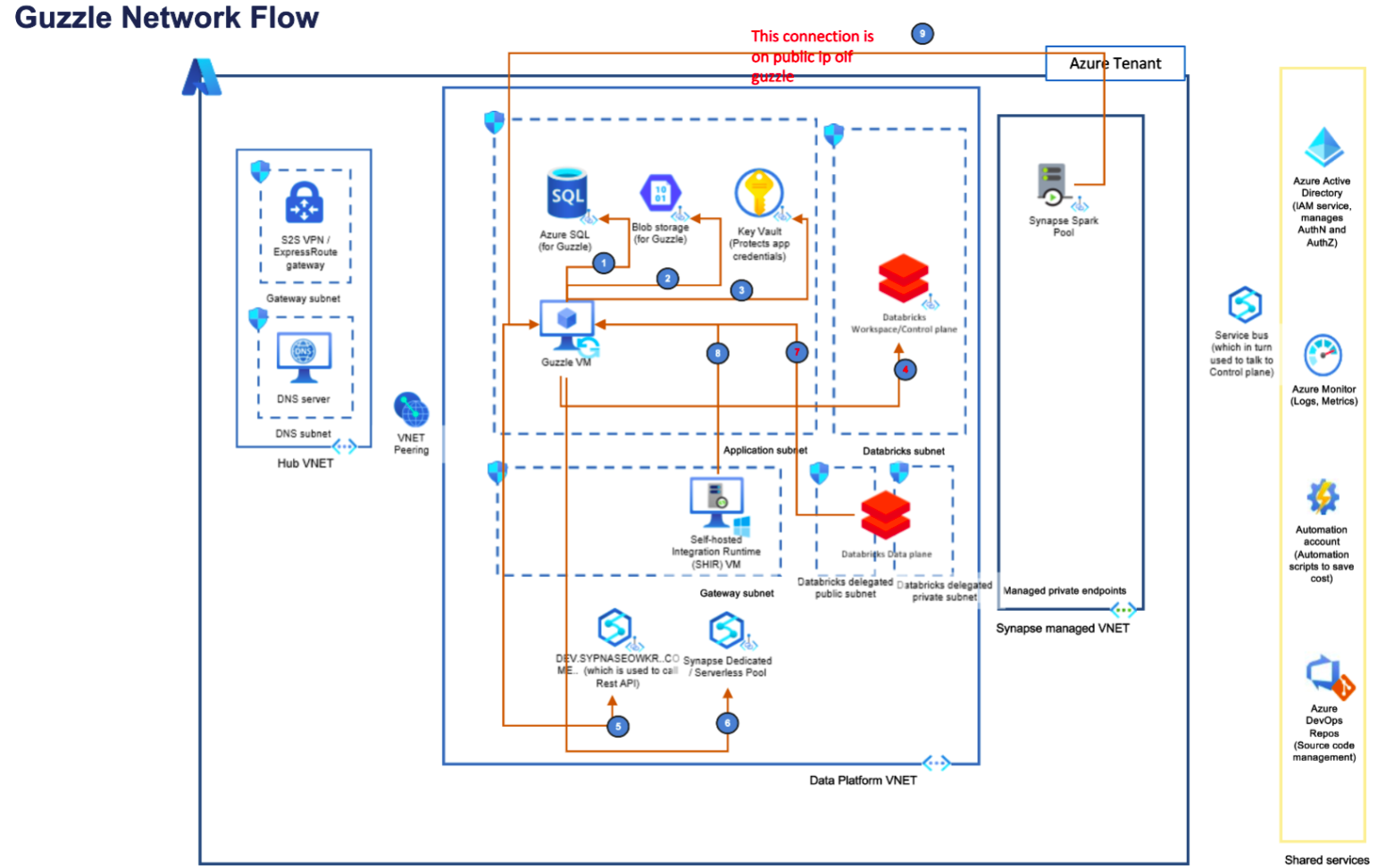
Guzzle Network Diagram for private endpoint#
| Resource | Azure Documentation Link | Purpose |
|---|---|---|
| Storage Account | Configure Azure Storage firewalls and virtual networks Use private endpoints - Azure Storage | Disable public access and create private endpoint to access blob privately. |
| SQL Server | Deny Public Network Access - Azure portal - Azure Database for MySQL | Disable public access and create 2 private endpoint: 1. Guzzle Vm 2. Synapse workspace |
| Key Vault | Integrate Key Vault with Azure Private Link | Disable public access on azure key vault and used as private endpoint |
| Synapse Private Endpoint | Access control in Synapse workspace how to - Azure Synapse Analytics | Add all private endpoint to synapse. 1. Storage Account 2. Key Vault 3. SQL Server 4. Private Link Service |
| Private Link Service With Load Balancer | Quickstart - Create a Private Link service - Azure portal - Azure Private Link | To access Guzzle VM in private network, we need to create private link service. |
| Guzzle API Setting | - | Change Guzzle API Setting with private link service fully qualified domain name. |
Guzzle VM Connection Table for private endpoint#
| # | Source | Target | Protocol / Port | Authentication Mechanism | Purpose of connection | Traffic Type |
|---|---|---|---|---|---|---|
| 1 | Guzzle VM | Storage Account for Guzzle | HTTPS | Managed Identity | To storage jars, third party library on blob for spark compute to read | Private |
| 2 | Guzzle VM | Azure SQL for Guzzle | HTTPS | AAD user credential / SAS | Read/write Guzzle audit and metadata | Private |
| 3 | Guzzle VM | Key Vault | HTTPS | Managed Identity | Get stored secrets and keys | Private |
| 4 | Guzzle VM | Databricks Control Plane | HTTPS | Managed Identity | Submit jobs to Databricks Cluster | Private |
| 5 | Guzzle VM | Synapse Control Plane | HTTPS | Managed Identity | Submit jobs to Spark Pool | Private |
| 6 | Guzzle VM | Synapse Dedicated Pool | HTTPS | Managed Identity | Submit jobs to Synapse dedicated pool | Private |
| 7 | Guzzle VM | Guzzle VM | HTTPS | Managed Identity | Update logs, retrieve configs from Guzzle | Private |
note
- Before running Job with Synapse it requires to have necessary guzzle setup.
Synapse Compute Support Matrix#
Please follow Guzzle official documentation for synapse compute support with different data sources. Click here.
Guzzle Configurations#
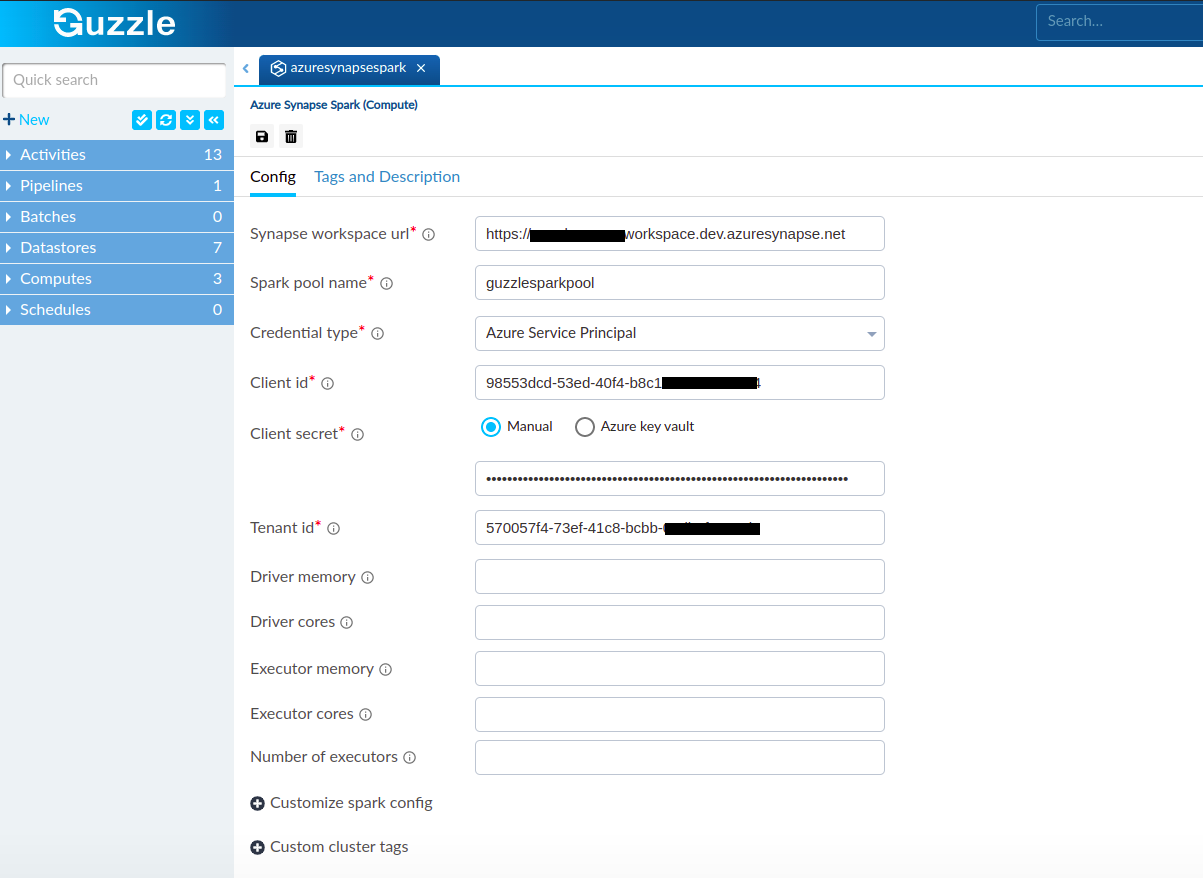
| Property | Description | Default Value | Required |
|---|---|---|---|
| Synapse workspace URL | Specify the URL of the Azure Synapse workspace. You will find this url as Development endpoint in Synapse workspace overview page in Azure portal | None | Yes |
| Spark pool name | Specify the spark pool name that will be used by Guzzle | None | Yes |
| Credential Type | Specify the credential type to connect to the Azure Synapse | Service principal | Yes |
| Client Id | Azure Active Directory provided client Id( also called an application ID). The register app in Azure Active Directory provides one unique id for associate to application. The client id of the created application in above steps. | None | Yes |
| Client Secret | Azure Active Directory Client Secret. Provide the client secret of the application that is created in above steps. Guzzle used this for verify and generate access key of the user authentication | None | Yes |
| Tenant Id | The unique identifier of the Azure Active Directory instance also called directory ID. A tenant represents an organization. Provide the tenant id of the application. It's a dedicated instance of Azure AD that an organization or app developer receives at the beginning of a relationship with Microsoft | None | Yes |
| Driver Memory | Specify the allocated driver memory for running jobs | None | No |
| Driver Cores | Specify the allocated driver cores for running jobs | None | No |
| Executor Memory | Specify the allocated executor memory for running jobs | None | No |
| Executor Cores | Specify the allocated executor cores for running jobs | None | No |
| Number of executors | Specify the number of spark executors you want the job to run | None | No |
| Customize spark config | Specify additional Spark configuration options. Specify the config name and config value | None | No |
| Custom cluster tags | Apply tags to the cluster. Specify the name of tag and value | None | No |
Run Guzzle Job with Synapse Spark#
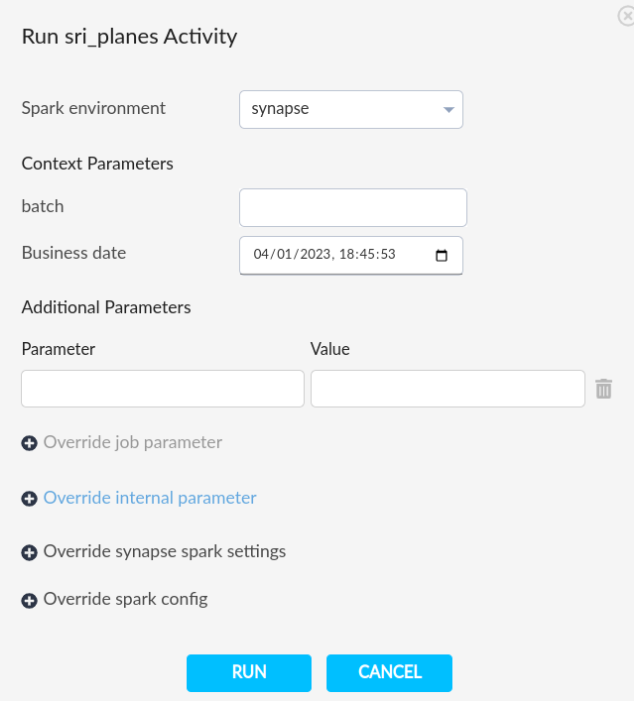
Guzzle Monitor UI#