Ingestion Datatype Validation
note
Datatype validation applies to Ingestion activity only.
Overview#
- The datatype validation feature is a way to validate source data against a given data type OR data type derived based on Inherit columns and datatype.


Story#
- While reading source, guzzle relay on spark to infer the schema of a given source, suppose in our case source is CSV with infer schema disabled, the column and their data type will be
- col1: String, col2: String, col3: String
- Afterward source's column data type can be changed using the
Transform SQLfeature, suppose we give the transform SQL tocol1as below- col1: transform SQL is
col1 || '0'then data type will determine at runtime which will beString
- col1: transform SQL is
- Suppose the target is Azure SQL as below
- col1: Int, col2: String, col3: Short
- Source has col1 as
Stringdata type and the target has col1 asIntdata type - In the source, if col1 contains all legal integers then the guzzle job will run successfully, but the CSV file will not guarantee the data type.
- In that case Datatype validation feature will help to filter non-integers numbers flowing into a target, not just that we can capture invalid records by using configuring the reject section.
- Either specify
IntExplicitly for col1 at data type text box
- Or change the Inherit columns and datatype to base on your use case, in our case Target Inherit columns and datatype will help, where the data type of source columns will be derived from the target accordingly

- If the data type is not specified then guzzle will derive according to the Inherit columns and datatype, a column that is not specified in the
Validation and Transformsection that column's data type validation flag will be determined by Inherit columns and datatype - In our case
- col1: we haven't specified any data type, so it will be
Intas per target and the validation datatype checked box has been checked. - col2: both data type and data type validation flag will be derived based on Target which is String and data type validation will happen.
- col3: both data type and data type validation flag will be derived based on Target which is Short and data type validation will happen and if guzzle found a non-short integer number then guzzle will filter those records.
- col1: we haven't specified any data type, so it will be


Inherit columns and datatype#
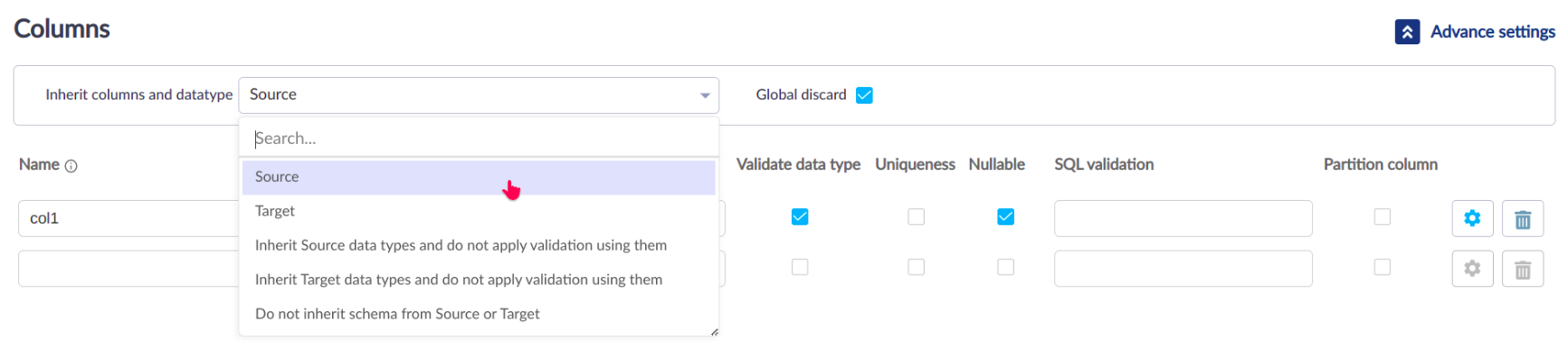
- While reading the source which data type allocate to source columns and whether the validation uses them or not.
- Source: This is a common and simple strategy where data type will be derived from the Source and validation will happen, this strategy can be used when we have multiple files with different schema.
- Target: Data type will be derived from Target and validation will happen, this strategy can be used when we have target oriented flow.
- Inherit Source data types and do not apply validation using them: This is the same as Source except guzzle will not perform the validation by default.
- Inherit Target data types and do not apply validation using them: This is the same as Target except guzzle will not perform the validation by default.
- Do not inherit schema from Source or Target: User define a schema if data type not specified then guzzle will implicitly take
String, and guzzle will only consider these columns to flow further.
Data type validation#
| Bigint | Int | Smallint | Tinyint | Double | Float | decimal(p, [s]) | Boolean | Varchar(n) | String | Timestamp | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BigInt | ✓ | Range check | Range check | Range check | x | x | x | ✓ | Length check | ✓ | x | x |
| Int | ✓ | ✓ | Range check | Range check | x | x | x | ✓ | Length check | ✓ | x | x |
| Smallint | ✓ | ✓ | ✓ | Range check | x | x | x | ✓ | Length check | ✓ | x | x |
| Tinyint | ✓ | ✓ | ✓ | ✓ | x | x | x | ✓ | Length check | ✓ | x | x |
| Double | x | x | x | x | ✓ | Range check | x | x | Length check | ✓ | x | x |
| Float | x | x | x | x | ✓ | ✓ | x | x | Length check | ✓ | x | x |
| Decimal(p, [s]) | x | x | x | x | x | x | Range check | x | Length check | ✓ | x | x |
| Bigint | Int | Smallint | Tinyint | Double | Float | decimal(p, [s]) | Boolean | Varchar(n) | String | Timestamp | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Boolean | x | x | x | x | x | x | x | ✓ | Length check | ✓ | x | x |
| String | Parse check | Parse check | Parse check | Parse check | Parse check | Parse check | Parse check | Parse check | Length check | ✓ | Parse check | Parse check |
| Timestamp | x | x | x | x | x | x | x | x | Length check | ✓ | ✓ | x |
| Date | x | x | x | x | x | x | x | x | Length check | ✓ | ✓ | ✓ |
- About range check, the range will be determined by java data type
- For instance, tinyint(byte) has range -128 to +127 if integer column value 200 try to validate against tinyint datatype guzzle will mark that record as invalid.
- About length check, guzzle will simply check the length of the column value
- about parse check.
- For date and timestamp datatype, guzzle will try to parse to spark default formats, in spark 3.3.0
yyyy-MM-ddis for date, andyyyy-MM-dd. HH:mm:ss.SSSSis for timestamp, for more information click here. - For numeric datatype (like BigInt, Double, Int, etc), guzzle will try to parse and also will perform the range check
- For date and timestamp datatype, guzzle will try to parse to spark default formats, in spark 3.3.0
- About ✓, guzzle will directly allow without touching data.
- About x, guzzle will directly disallow without touching data.