Working with Hive Database
note
Only supported on Databricks compute
Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data query and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
This article outlines how to use Hive as a source or target in Ingestion activity. Ingestion Active lets you leverage this native connector offered by Databricks and allows you to specify different configurations that are supported by this connector.
Apache Hive as a Source#
note
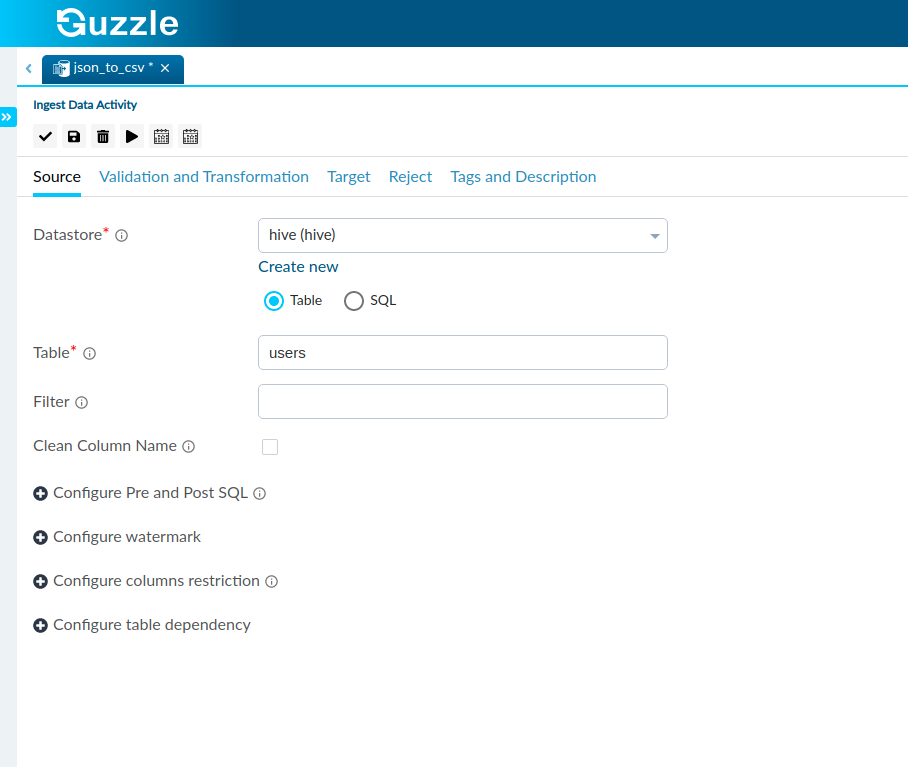
In the Datastore section we can choose to read four Data either as a Table or through SQL (in the form of a query).
| Property | Description | Default Value | Required |
|---|---|---|---|
| Table + Filter | Specify the table from where to read data. The table can contain schema and also database name. We can specify the Schema Name along with the Table Name. If it is not specified it is taken from the Datastore. Also, when the Table option is selected, you can also specify the Filter. The filter can be used to select only a part of the table. We may basically enter a condition and only the part of the table that satisfies the condition will be seen in the Target Section. | None | Yes. |
| SQL | Specify the SQL query which will be run as-is on the source | ||
| Clean Column Name | To specify whether to clean the column names of source data (both file headers and column names from table). All the characters other than alphanumeric will be converted to _. Ex. 'col.1' will become 'col_1', 'col@1' will become 'col_1' | False | No |
| Configure Pre and Post SQL | Guzzle supports Pre-SQL and Post-SQL for source and target and their execution in ingestion. It is mainly used for pre and post formatting of data in database. For more information click here. | NULL | No |
| Configure Watermark | A watermark represents tracking the last loaded value for one or more columns for a given source table or source SQL to enable loading data incrementally. Using watermark columns is one of the mechanisms used for changed data capture (CDC). For more information click here. | NULL | No |
| Configure columns restriction | Mention column names and choose from the options to exclude and include columns. For more information click here. | NULL | No |
| Configure table dependency | NULL | No |
Interface for Hive database as source is#
Apache Hive as a Target or Reject#
| Property | Description | Default Value | Required |
|---|---|---|---|
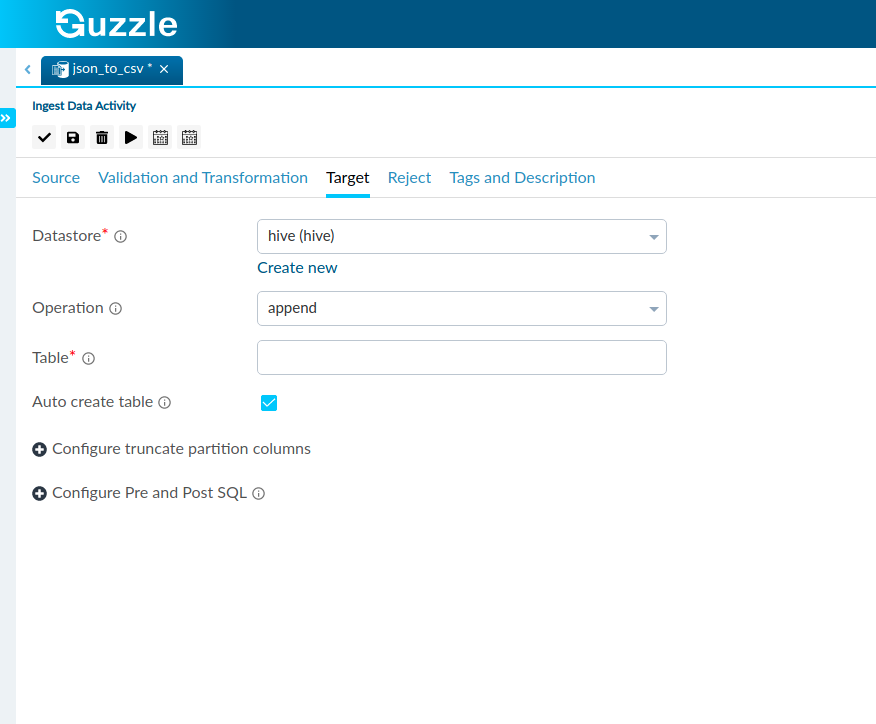
| Table | This is used to specify the Target Table we would like to create based on our Source. | None | Yes |
| Operation | Provides two options that determines whether the source content or records are expected to be appended or overwritten in order to disallow existing data- Append: To atomically add new data to an existing target table. Overwrite: To atomically replace the data in a target table with source table. The partition columns are detected based on the source. For more information click here. | Append | Yes |
| Auto create table | Guzzle provides the Auto Create Table feature in the Target Section. When selected it will automatically create a Target Table for us with the name as specified in the Table section above. In the schema section we have the Partition indicator. This indicator is used when guzzle auto creates a table for Hive to decide the partition column. The order of partition columns will be according to how it appears in the Schema Section. This can be seen in the figure below: | True | Yes |
| Configure truncate partition columns | Specify the target table partition column names and its values to truncate(delete) the target table partitions before writing into the table. For more information click here. | NULL | No |
| Configure pre and post sql | Guzzle supports Pre-SQL and Post-SQL for source and target and their execution in ingestion. It is mainly used for pre and post formatting of data in database. For more information click here. | NULL | No |
Interface for Hive database as target is#
note
When Guzzle creates a Table using the Auto Create Table option it will use the Partition Column Setting to determine the Partition Columns to use. The sequence will be as per the order specified.