Working with JDBC Database
Java Database Connectivity (JDBC) is an application programming interface (API) for the programming language Java, which defines how a client may access a database. It is a Java-based data access technology used for Java database connectivity.
This article outlines how to use JDBC as source or target in Ingestion activity. Ingestion Active lets you leverage this native connector offered by Databricks and allows you to specify different configurations that are supported by this connector.
JDBC as a Source#
note
In the Datastore section we can choose to read full Data either as a Table name or through SQL query (in the form of a query).
| Property | Description | Default Value | Required |
|---|---|---|---|
| Table + Filter | Specify the table from where to read data. [database name].[schema name].[table name] Note: Depending on the database technology used: [database name] and [schema name] can be optionally specified along with the table name. Database name and JDBC URL all this will be stored in datastore. In source or target section we have to select datastore name and give table name and give filter (if required). | ||
| Along with the Table option, you can also specify the Filter property — which is SQL filter condition in native SQL of the underlying JDBC technology to filter subset of records from the table | None | Yes. | |
| SQL | Specify the SQL query which will be run as-is on the source | None | Yes |
| Clean Column Name | To specify whether to clean the column names of source data (both file headers and column names from table). All the characters other than alphanumeric will be converted to _. Ex. 'col.1' will become 'col_1', 'col@1' will become 'col_1' | False | No |
| Configure Pre and Post SQL | Guzzle supports Pre-SQL and Post-SQL for source and target and their execution in ingestion. It is mainly used for pre and post formatting of data in database. For more information click here. | NULL | No |
| Configure watermark | A watermark represents tracking the last loaded value for one or more columns for a given source table or source SQL to enable loading data incrementally. Using watermark columns is one of the mechanisms used for changed data capture (CDC). For more information click here. | NULL | No |
| Configure columns restriction | Mention column names and choose from the options to exclude and include columns. For more information click here. | NULL | No |
| Configure table dependency | NULL | No |
Example of a JDBC source without a filter:#
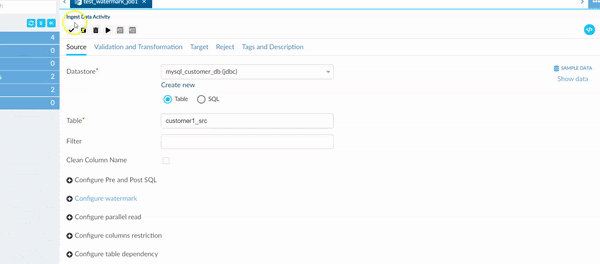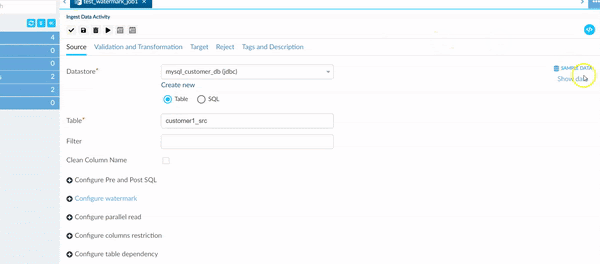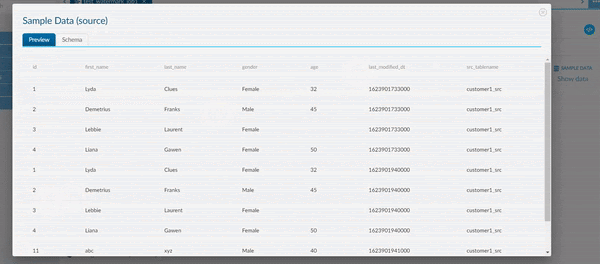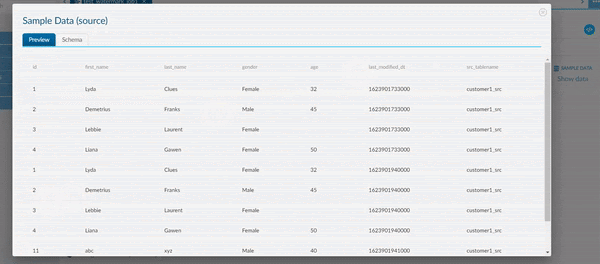
In the animation above, no filter has been applied to our JDBC source. Hence, the entire Source Data is visible when we Sample our Data.
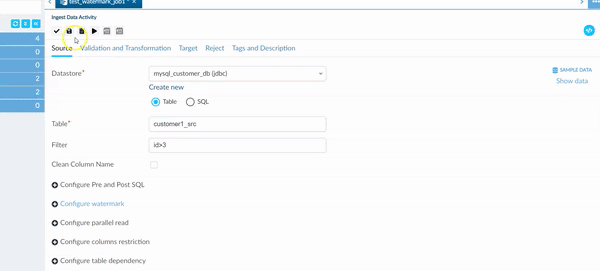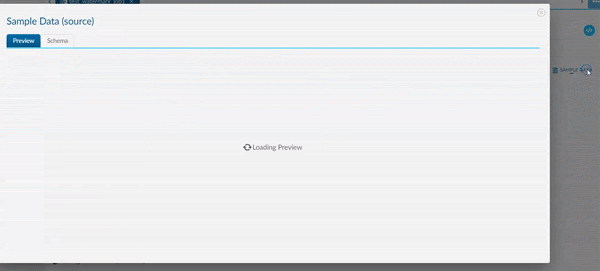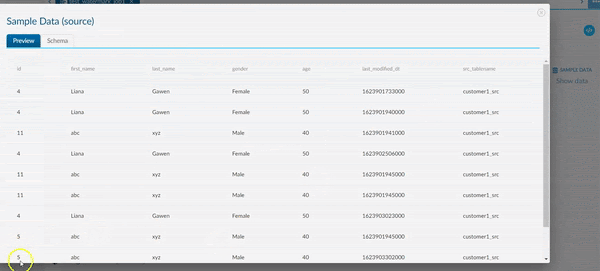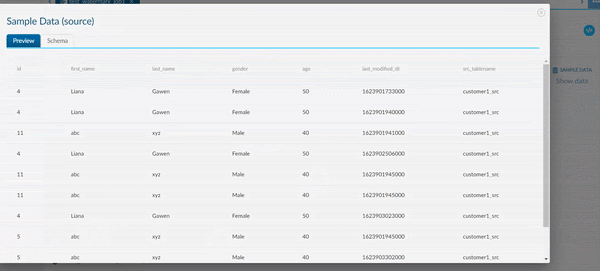
Example of a JDBC source with a filter:#
In the animation below, we add a filter to the column ID that is ID>3. In the Sample Data we now only see the Data entries which satisfy this condition.
JDBC as a Target or Reject#
| Property | Description | Default Value | Required |
|---|---|---|---|
| Table (In Target /Reject Section) | To specify the Target Table where the data from source is loaded. The data is always appended to target table | None | Yes |