AWS Databricks
Guzzle supports Computing environments on the AWS Cloud. In Guzzle AWS cloud setup, we can use Databricks to execute our workloads. This article helps in using AWS Databricks as a computing environment in Guzzle.
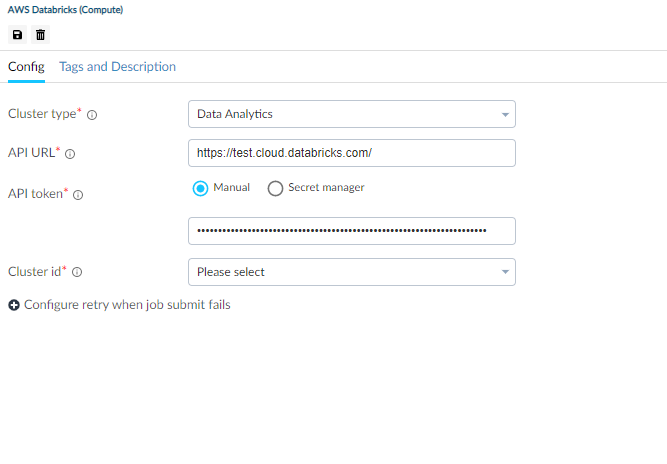
Use of AWS Databricks as a computing environment#
| Property | Description | Default Value | Required |
|---|---|---|---|
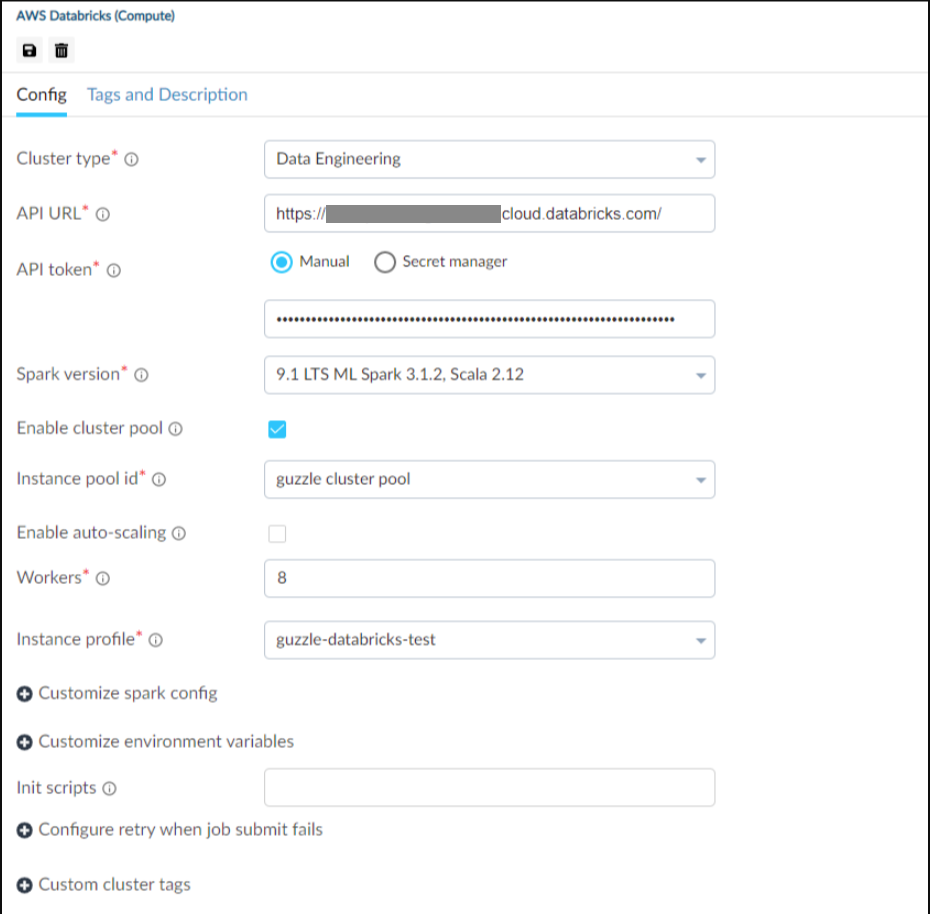
| Cluster type | There are 2 types of Databricks clusters available in Guzzle: Data Engineering : Data engineering cluster is recommended for automated workloads. It is recommended to use it for your BAU data loads. Data Analytics : Data analytics cluster is recommended for interactive queries along with concurrent user support. This cluster type is configurable in Guzzle, and it can also execute the workloads, but it is not recommended to use it for your BAU data loads. Data Analytics cluster is costlier than Data Engineering cluster for per DBU usage and meant for interactive queries through Databricks notebook in a shared environment where multiple people have to collaborate as a team. | Data Engineering | True |
| API URL | Specify AWS Databricks environment URL. | None | True |
| API token | Specify Databricks access token for authentication and to communicate with AWS databricks environment. User can generate token from databricks workspace using User Settings -> Access Tokens -> Generate new token option. To specify the token following options are available: 1. Manual: Provide api token directly. 2. Secret Manager: Use it through AWS Secret manager feature. Give value of the secret name where api token is stored in AWS secret manager instance. | None | Yes |
| Cluster id (applicable for data analytics cluster) | Specify analytics cluster name which is precreated in Databricks environment. Guzzle will show available clusters once a valid API token and URL are configured. UI will show cluster name, but it stores cluster ID in the underlying YML file | None | Yes |
| Configure retry when job submit fails | Enable job resubmittion when Guzzle is not able to successfully submit the job (possibly due to issues like unavailability of cloud resources or error in control plane). by default, Guzzle not perform any retry when job submittion failed. Max retry: Provide the number of maximum retry Min retry interval: Provide the interval time between retry in milliseconds | None | No |
| Spark version (applicable for data engineering cluster) | Select the spark version that will run on cluster. This drop-down is populated once a valid API token and URL are provided. | None | Yes |
| Enable cluster pool | To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances, for the driver and worker nodes. | False | No |
| Instance pool id (applicable when cluster pool is enableded) | Specify the predefined pool from the drop-down. Available predefined pools are listed in the drop-down once a valid API token and URL are configured. | None | Yes |
| Driver node type (applicable for data engineering cluster) | Specify the instance type for the driver node. | None | Yes |
| Worker node type (applicable for data engineering cluster) | Specify the instance type for the worker node. | None | Yes |
| Workers | Specify the Fix number of workers to use in cluster. | 8 | Yes |
| Enable autoscaling | Enable autoscaling to choose the appropriate number of workers for job, whose requirements changes over time or requirements are unknown. | False | No |
| Min workers (applicable when autoscaling is enableded) | Specify the minimum number of workers to use in cluster. | 2 | Yes |
| Max workers (applicable when autoscaling is enableded) | Specify the maximum number of workers to use in cluster. | 8 | Yes |
| On-demand nodes | The on-demand size determines the number of on-demand nodes. The rest of the nodes in the cluster will attempt to be spot nodes. The driver will be on demand. | 1 | Yes |
| Spot fall back to on-demand | If the EC2 spot price exceeds the bid, use on-demand instances instead of spot instances. This applies during both creation and lifetime of the cluster. | False | No |
| Max spot price | Max price you are willing to pay for Spot instances. | 100 | Yes |
| Instance profile | Instance profile is used to securely access AWS resources without using AWS keys. Click here for more information about how to create and configure instance profiles. Once you have created an instance profile, you can select it in the Instance Profile drop-down list. Make sure your instance profile has permission to access the guzzle config storage and secret manager. | None | Yes |
| Availability zone | Select a specific cluster availability zone where your cluster will launch. | None | Yes |
| Enable local storage auto-scaling | If you don’t want to allocate a fixed number of EBS volumes at cluster creation time, use autoscaling local storage. When worker begins to run too low on disk, it automatically attaches a new EBS volume to the worker before it runs out of disk space. | False | No |
| EBS volume type (applicable when local storage auto-scaling is disabled) | For instance types that do not have a local disk, or if you want to increase your Spark shuffle storage space, you can specify additional EBS volumes. Consider the 'Enable local storage auto-scaling' option if you are not sure how to size them. | None | No |
| Volume counts (applicable when local storage auto-scaling is disabled) | Provision the number of volumes for each instance. Users can choose up to 10 volumes per instance. | None | No |
| Volume size in GB (applicable when local storage auto-scaling is disabled) | The size of each EBS volume (in GB) for each instance. For general purpose SSD, this value must be within the range 32 - 4096. For throughput optimized HDD, this value must be within the range 500 - 4096. | None | No |
| Customize spark config | Used to provide custom Spark configuration properties in a cluster configuration Ex: conf : spark.sql.broadcastTimeout value : 5000 | None | |
| Customize environment variables | Used to specify environment variables to use in spark computes. Ex: Variable : MY_ENVIRONMENT_VARIABLE. Value : VARIABLE_VALUE | None | |
| Init script | Configure cluster node initialization or init-script that is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts. You can use init scripts to install packages and libraries not included in the Databricks runtime, modify the JVM system classpath, set system properties and environment variables used by the JVM, or modify Spark configuration parameters, among other configuration tasks. | None | |
| Custom cluster tags | Cluster tags allow you to easily monitor the cost of cloud resources used by various groups in your organization. You can specify tags as key-value pairs, it applies to cluster and its cloud resources like VMs and disk volumes, as well as DBU usage reports. | None |
Interface of AWS Databricks compute for cluster type : Data Engineering#
Interface of AWS Databricks compute for cluster type : Data Analytics.#