Azure Databricks
Guzzle supports Computing environments on the Azure Cloud. In Guzzle azure cloud setup, we can use Databricks to execute our workloads. This article helps in using Azure Databricks as a computing environment in Guzzle.
Use of Azure Databricks as a computing environment#
| Property | Description | Default Value |
|---|---|---|
| Cluster Type | There are 3 types of Databricks clusters available in Guzzle: Data Engineering : Data Engineering cluster is recommended for automated workloads. It is recommended to use it for your BAU data loads. Data Analytics : Data Analytics cluster is recommended for interactive queries along with concurrent user support. This cluster type is configurable in Guzzle, and it can also execute the workloads, but it is not recommended to use it for your BAU data loads. Data Analytics cluster is costlier than Data Engineering cluster for per DBU usage and meant for interactive queries through Databricks notebook in a shared environment where multiple people have to collaborate as a team. Data Engineering Light : Data Engineering Light cluster is even cheaper than Data Engineering cluster for per DBU usage. Once you select this type, rest all the other configuration for this cluster type would be the same as the Data Engineering cluster. Note that, Data Engineering Light provides a runtime option for jobs that don’t need the advanced performance, reliability, or autoscaling benefits provided by the more capable Databricks Data Engineering cluster offering. | Data Engineering |
| API URL | It is used to specify the URL of the Databricks environment which will be used with Guzzle. We can specify the Azure region accordingly based on the region of the Databricks workspace. | None |
| API Token | It is used to specify the API Token for our Databricks Environment. API token is required for Guzzle to authenticate to Azure Databricks. API token needs to be generated from the Databricks workspace. Specify the api token of Azure Databricks Cluster. For specify the token following options are available: 1. Manual: Provide api token directly. 2. Azure Key Vault: To use Azure key vault feature user have to integrate Key Vault with Guzzle for that visit here. Give value of the key vault name and secret name where api token is stored in Azure Key Vault instance. | None |
| DBFS Guzzle Directory | It is used to specify the Guzzle mount directory location where guzzle job configs, jars and all bin relies on in the Databricks. | None |
| Cluster Id (Applicable for Data Analytics cluster) | It is used to specify the name of the Cluster we have created in the Databricks Environment. A job cluster is created in Databricks with this name. Guzzle will show available clusters once a valid API key is provided. UI will show cluster name, but it stores cluster ID in the underlying YML file | None |
| Configure Retry Options | basically is the retry which we do if Guzzle is not able to successfully submit the job (possibly due to issues like unavailability of cloud resources or error in control plane) | None |
| Spark Version (Only in Data Engineering and Data Engineering Light) | Specify the Spark Version we have used in creating our cluster in the Databricks environment. These drop-downs are populated once valid API keys and URLs are provided. | None |
| Enable Cluster Pool | Used to specify To attach a cluster to a pool. | False |
| Instance Pool ID | select the pool from the drop-down when you configure the cluster. Available pools are listed at the top of each drop-down list. You can use the same pool or different pools for the driver node and worker nodes. | None |
| Driver Node Type (Only in Data Engineering and Data Engineering Light) | It is used to specify the type of driver we would like to use as our Driver Node. | None |
| Worker Node Type (Only in Data Engineering and Data Engineering Light) | Specify the workers we would like to use in our Databricks environment | None |
| Enable AutoScaling | A cluster that automatically scales between the minimum and maximum number of nodes, based on load. | False |
| Customize Spark Config | Used to specify additional spark config options Ex: conf : spark.sql.broadcastTimeout value : 5000 | None |
| Customize Environment Variables | Used to specify environment variables to use in spark computes. Ex: Variable : GuzzleHome. Value : /mnt/guzzle/guzzle | None |
| Init Script | Cluster-scoped init scripts are init scripts defined in a cluster configuration. You can put init scripts in a DBFS or ADLS directory accessible by a cluster. And give the location to that script in guzzle spark computes | None |
| Custom Cluster Tags | You apply tags to your Cluster. Each tag consists of a name and a value pair | None |
For sensitive spark configuration, one should use Databricks secrets instead of using plain values as they will be visible in to configure. This could be a storage account access key.
Setup Databricks Workspace#
Once you enter all necessary fields, the user has to set up the workspace on Databricks through click on setup workspace from the tab bar.
On click of setup workspace guzzle will create a notebook known as setup-guzzle.scala in the Databricks workspace.
In the notebook guzzle programmatically mount shared storage in the Databricks environment.
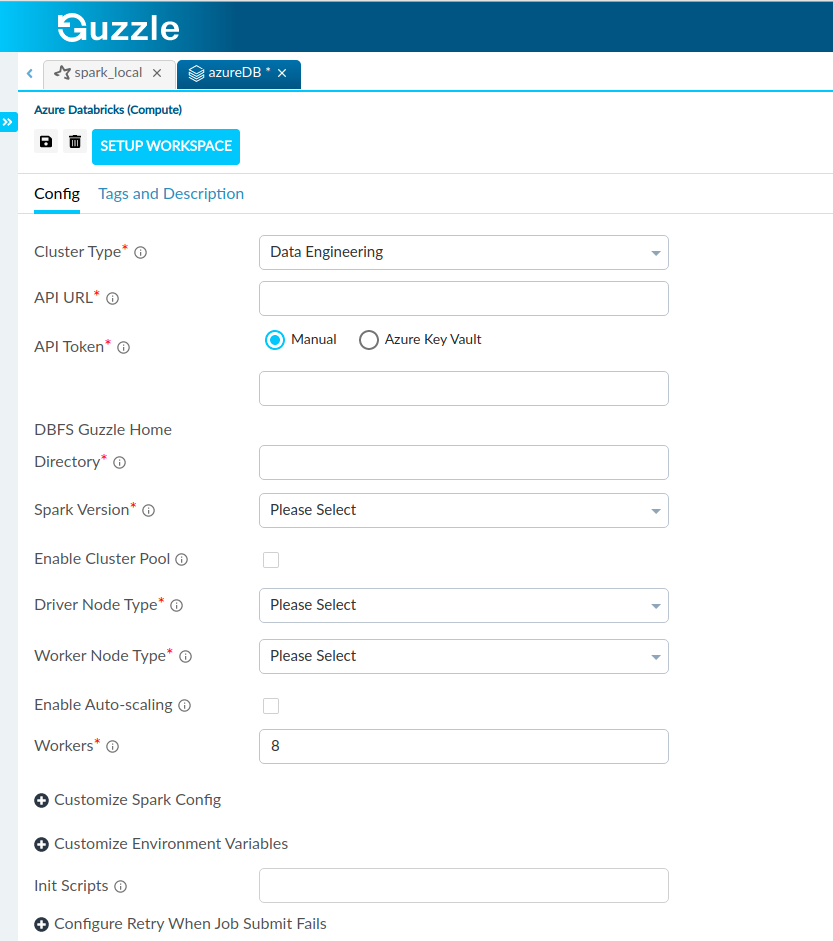
Interface of Azure Databricks compute for cluster type : Data Engineering and Data Engineering Light.
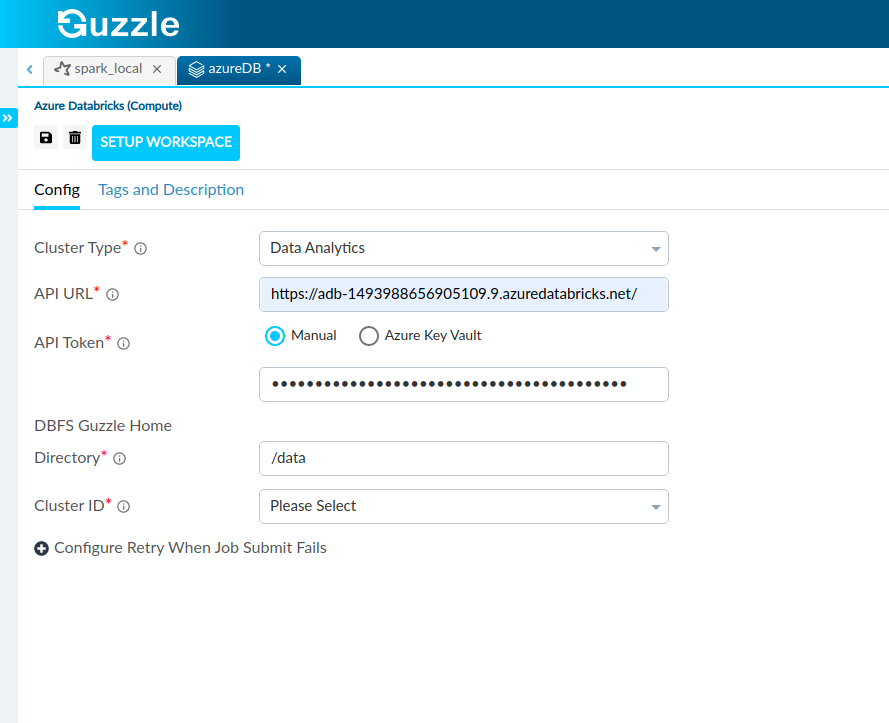
Interface of Azure Databricks compute for cluster type : Data Analytics.
how to setup external metastore#
One can use init script or spark configs. More details of can be found here
A typical set of spark configuration when using Azure SQL server are external metastore are: