Working with JSON Files
JavaScript Object Notation (JSON) is a standard text-based format for representing structured data based on JavaScript object syntax. It is commonly used for transmitting data in web applications. JSON is a language-independent data format.
note
JSON file support in Guzzle provides extensive features to specify file format details and many other properties which make it easier to work with our Data. This article outlines how to work with JSON files for source and target in Ingestion activity.
JSON File Properties in Guzzle#
| Property | Description | Default Value | Available in Source Section | Available in Target Section |
|---|---|---|---|---|
| Character Set | It refers to the Set of Characters used to Read/Write test files. Allowed Values include: UTF-8, UTF-16 etc. | UTF-8 | ✔ | X |
| Override JSON root path | It can be used to specify an object or location where we want to take our data from. For e.g.- If we want to focus on one particular column of our data we can specify the Column name here. Example : { "id" : 1, "name" : { "first_name" : "ABCD", "last_name" : "XYZ" }, "age" : 10 } if we give name as a value than it will fetch data first_name and last_name and consider name as a root node. | None | ✔ | X |
| Multi-Line | This is applicable when a single data record spans across multiple lines. This applies to both JSON files which are in array form or separate JSON documents. | False | ✔ | X |
| Configure processed path | The Configure Processed Paths feature allows the user to specify the directory and Guzzle moves the Data into that directory. When creating a processed file path Guzzle creates 3 subfolders: processed, rejected and partial. For more information click here. | NULL | ✔ | X |
| Configure control file settings | The Configure Control File feature cross check whether a file is valid or not. It compares the number of records in the original file and the control file extension. Guzzle provides the Configure Control File feature for all local file formats including Delimited, JSON, XML, Excel and Fixed Length Files. For more information click here. | NULL | ✔ | ✔ |
| Partial Load | Specify partial loading of files. | False | ✔ | X |
The Interface for the JSON Format for both Source#
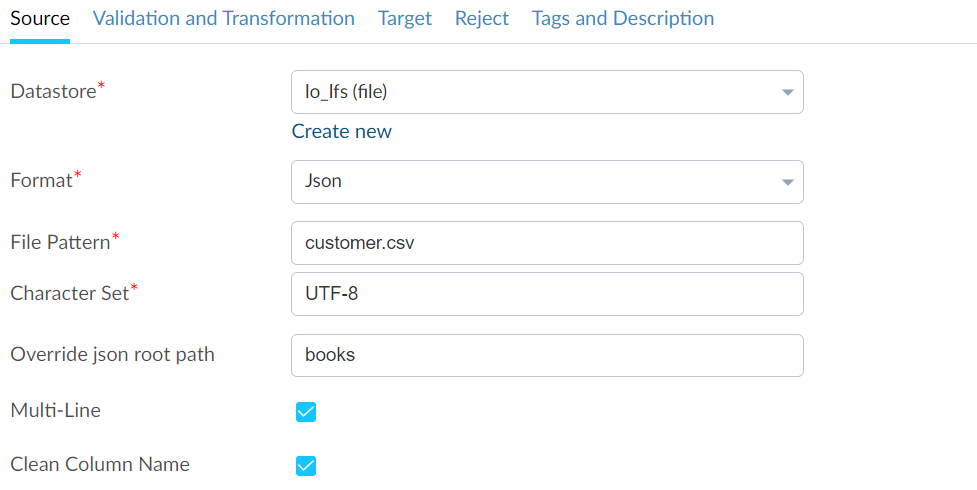
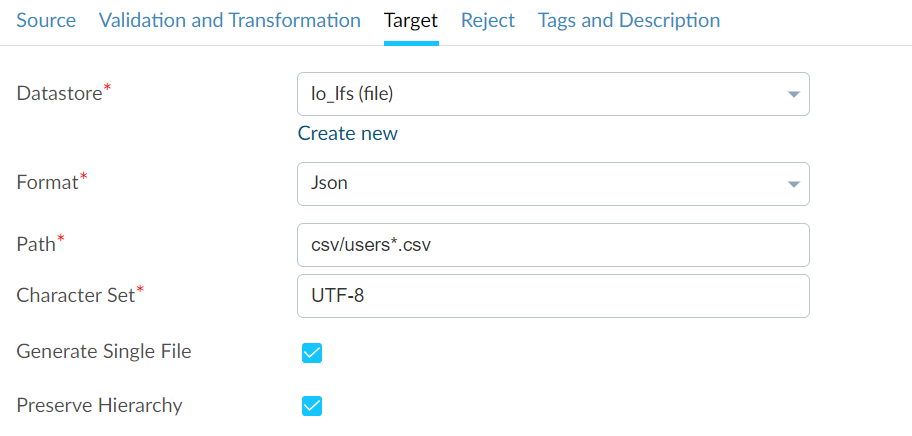
The Interface for the JSON Format for both Target#
Multiline:#
Each line must contain a separate, self-contained valid JSON object.
Example:
When Multi-line is true Guzzle expects Data in the following way:
regular multi-line JSON file or entire file is a singular JSON object / array
it should be one singular valid JSON object / array
note
every object in that array or object is separated by commas (because that single JSON object/array should valid)
for example:
[
]
{
}
Illustrations#
JSON file containing with single object separated
{"id": 0001, "name": "John", "address": “Broward County”}
{"id": 0002, "name": "Lynda", "address": “Velcore line”}
{"id": 0003, "name": "Roan", "address": “Tarbell street”}
Multiline : true
Sample Output when multiline is true is shown below:
| ID | name | address |
|---|---|---|
| 001 | John | Broward County |
Sample Output when multiline is false is shown below:
| ID | name | address |
|---|---|---|
| 001 | John | Broward County |
| 002 | Lynda | Velcore line |
| 003 | Roan | Tarbell street |
JSON file containing array with multi line#
Sample source data (Customer.json) :
[
]
When multiline is set to false Guzzle will treat the entire file like a single JSON object.
Job Config (json_with_multiline_false):
version: 1 job: type: ingestion source: endpoint: local files properties: source_file_pattern: json/customer1.json format: json charset: UTF-8 partial_load: false format_properties: clean_column_name: false multiline: false
Sample Output when multiline is false is shown below:
| ID | name | addresses |
|---|---|---|
| 0001 | John | [[1001, Broward County],[1002, Velcore line]] |
When multiline is set to true Guzzle will treat the entire file like a single JSON object.
Job Config (json_with_multiline_true):
version: 1
job:
type: ingestion
source:
endpoint: local files
properties:
Sample Output when multiline is True is shown below:
| ID | name | addresses |
| 0001 | John | [[1001, Broward County], [1002, Velcore line]] |
| 0002 | Lynda | [[1001, Broward County], [1002, Velcore line]] |
| 0003 | Roan | [[1001, Broward County], [1002, Velcore line]] |
note
Every object in the array is separated by a comma
Column Mapping in JSON Files#
We can also add Column Mapping to specify how to map columns in the source file. This is applicable for files which are having headers or without header. Column Mapping in JSON helps in mapping the columns to a new Column Name as shown here:
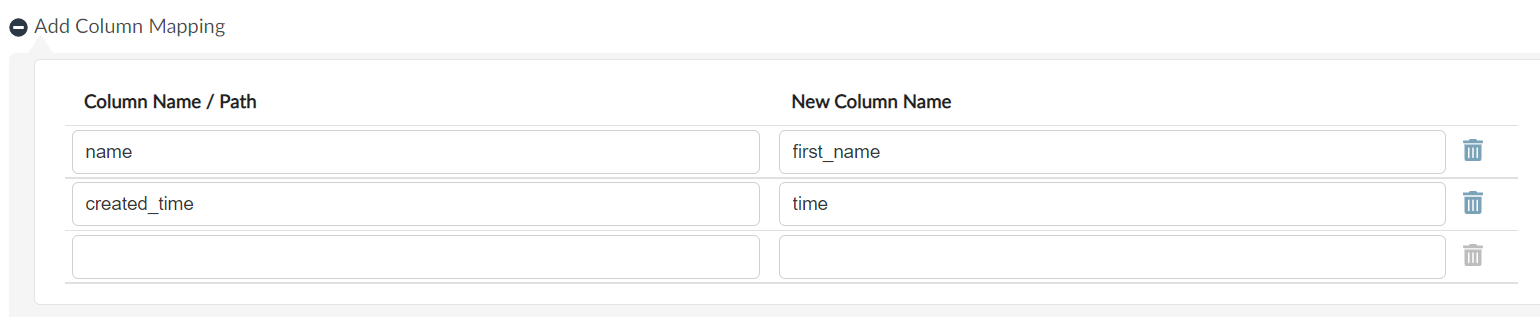
Here we have mapped the columns to a new Column Name. name is mapped to first_name and created_time is mapped to time.#
x
{"id": 0001, "name": "John", "address": “Broward County”}
{"id": 0002, "name": "Lynda", "address": “Velcore line”}
{"id": 0003, "name": "Roan", "address": “Tarell street”}
Config:
version: 1
job:
type: ingestion
source:
endpoint: json_files
properties:
column_mapping:
Sample output:
| customer_id | first_name | address_line1 |
|---|---|---|
| 0001 | John | Broward County |
| 0002 | Lynda | Velcore line |
| 0003 | Roan | Tarrel street |
If file has multiline (Customer.json)#
column_mapping:
Sample Output
| ID | name | address_line1 | addresses |
|---|---|---|---|
| 0001 | John | Broward County | [[1001, Broward County], [1002, Velcore line]] |
| 0002 | Lynda | Velcore line | [[1001, Broward County], [1002, Velcore line]] |
| 0003 | Roan | Tarrel street | [[1001, Broward County], [1002, Velcore line]] |