Spark Parameters
- When working with Apache Spark, you can utilize various parameters to configure and optimize your Spark jobs. These parameters can be set at different levels, such as activity, pipeline and batch depending on your specific requirements.
- We can use Spark parameter for various ways, For example, we can use parameters to change spark cluster to higher configurations at runtime level.
- In Guzzle, we can pass or override spark related parameters.
- There are 4 ways we can pass spark parameters in guzzle
- Pipeline activity level (Passing spark parameters in activity level in pipeline which will applicable to particular activity)
- Pipeline level (Configuration Override)
- Activity level (Activity Configurations)
- Pipeline level (Applicable to all activity inside the pipeline)
- Runtime dialog
- Override spark config/Override databricks settings
- Additional parameters
- Environment Parameter
- Pipeline activity level (Passing spark parameters in activity level in pipeline which will applicable to particular activity)
Activity inside pipeline (Highest Precedence)#
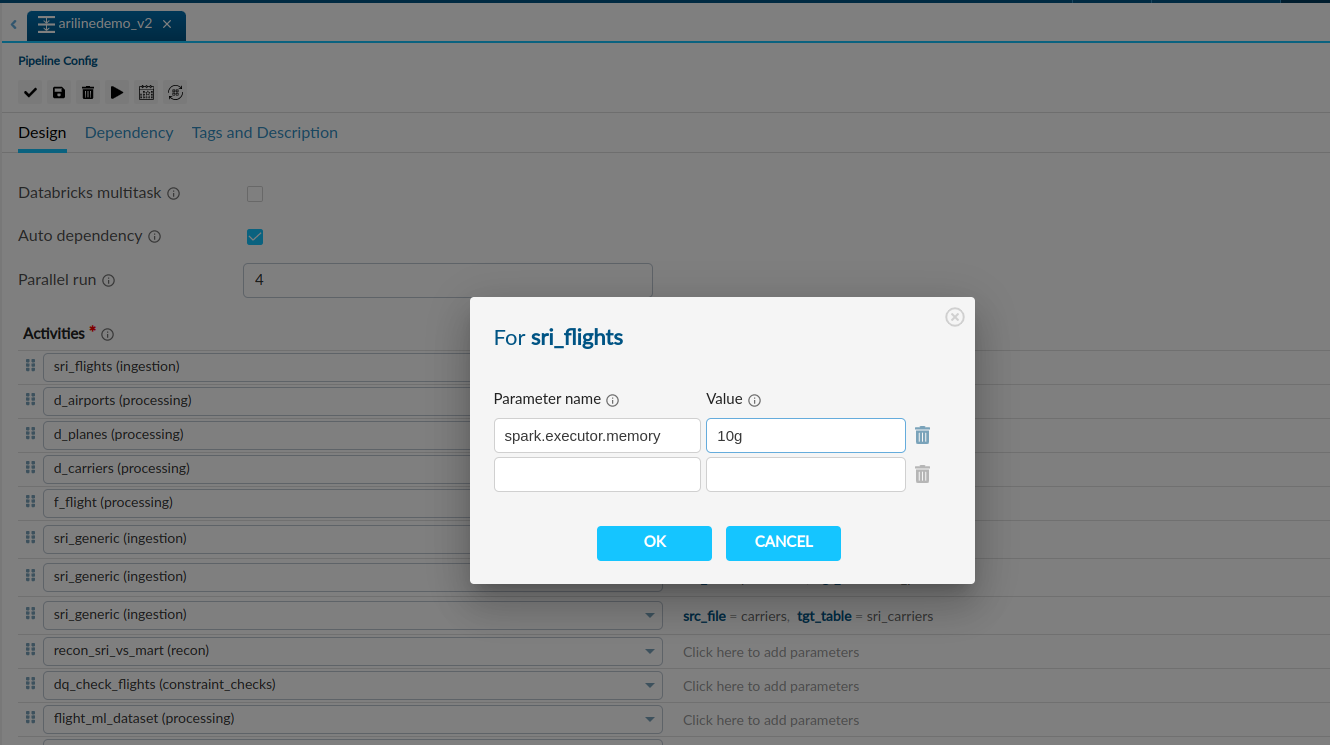
- You can set spark configurations at activity level inside pipeline from setting icon in pipeline list.
- You can consider spark configurations of each activity individually.
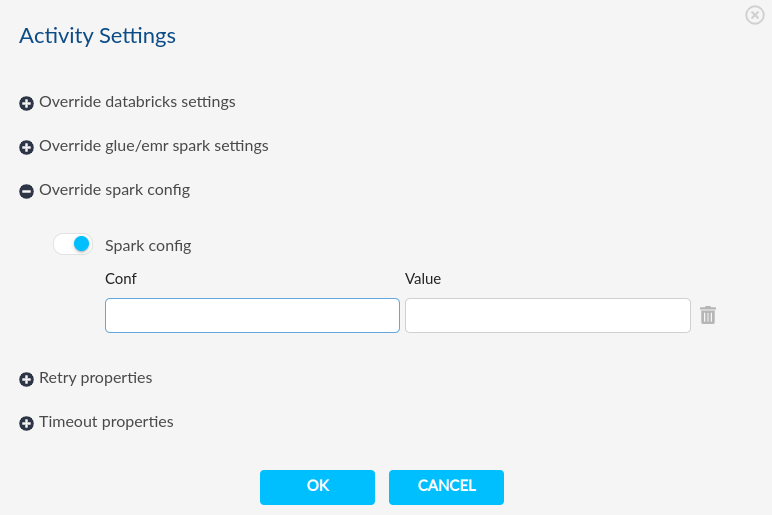
Activity Level
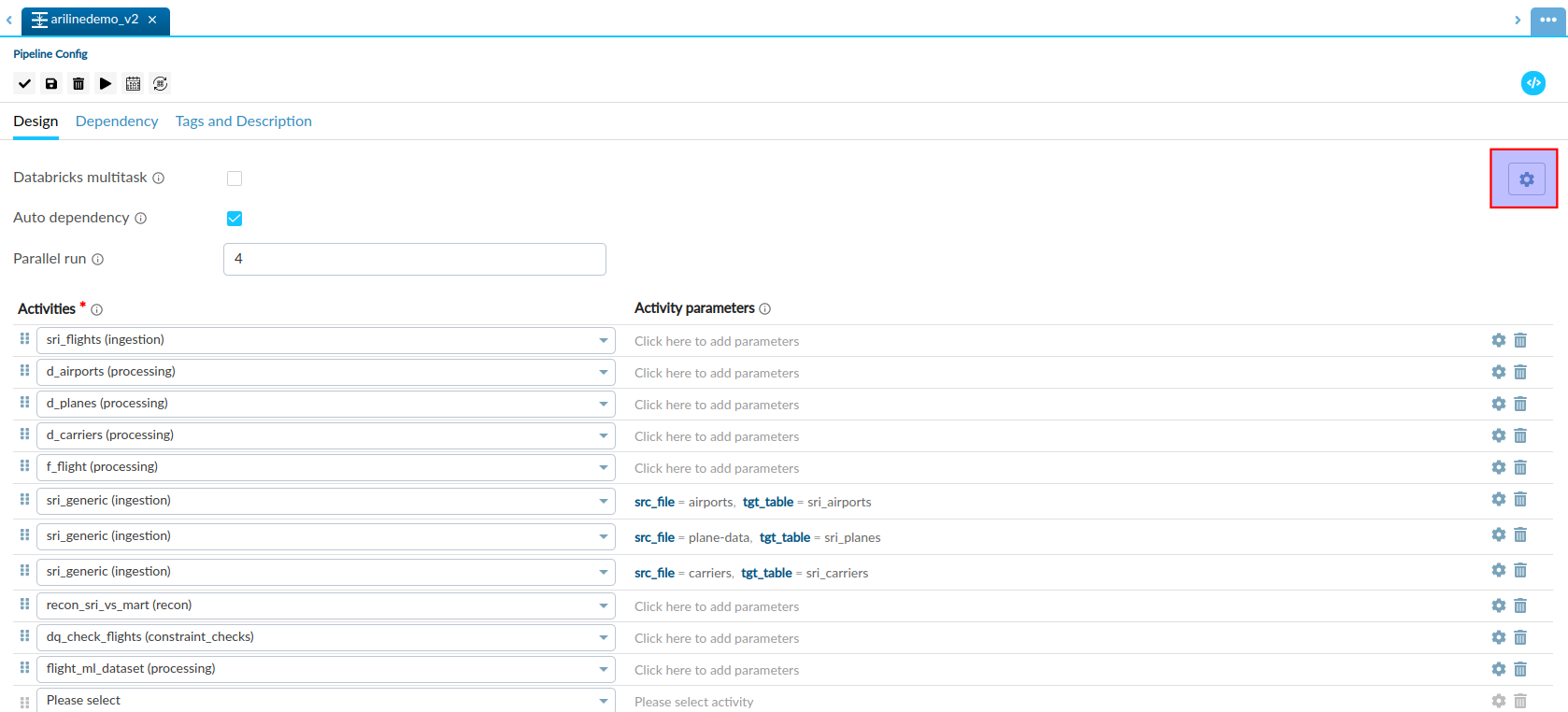
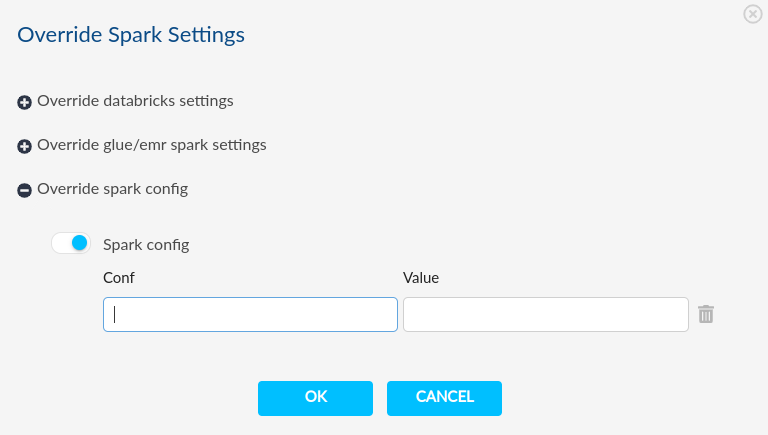
Pipeline Level#
- We can provide common spark configurations for all mentioned activities in pipeline.
- If we have not mention spark config in activity inside pipeline then guzzle will take precedence of pipeline configurations.
Pipeline Runtime#
- If we have not specify the activity and pipeline level then we can set spark parameter at runtime.
- Guzzle will pass spark parameter to each activities inside the pipeline
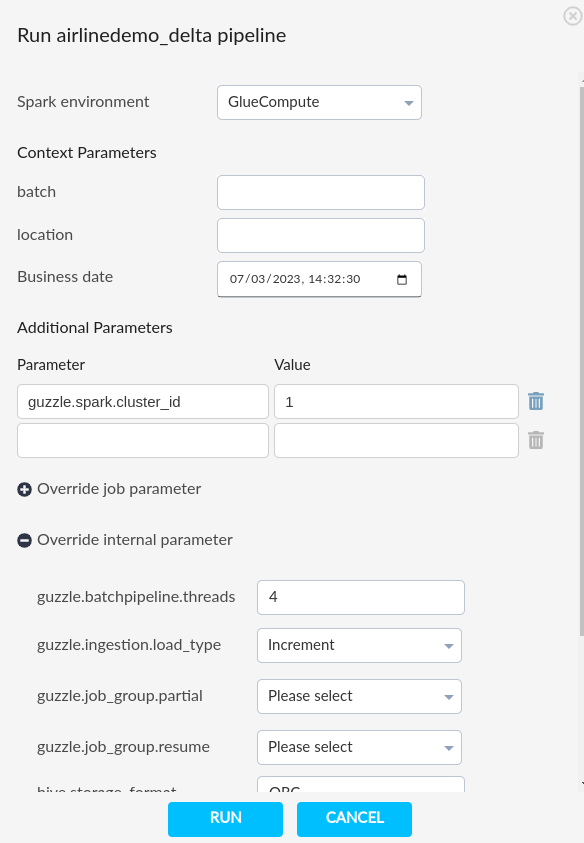
Environment Variable#
- We can also use environment variables to define spark configurations. Guzzle will consider lowest precedence of it.
Compute specific Spark Configs#
Databricks#
| Parameter | Parameter Name | Default Value | Description |
|---|---|---|---|
| Cluster id | guzzle.spark.cluster_id | - | You can set databricks cluster ID in which job will executed |
| Spark version | guzzle.spark.spark_version | - | Databricks Runtime is the set of core components that run on your clusters. All Databricks Runtime versions include Apache Spark and add components and updates that improve usability, performance, and security. |
| Enable cluster pool | guzzle.spark.instance_pool_id | - | Here we can attach cluster pool to the databricks cluster |
| Enable auto-scaling | guzzle.spark.workers.autoscale.min_workers guzzle.spark.workers.autoscale.max_workers | - | To allow Databricks to resize your cluster automatically, you enable autoscaling for the cluster and provide the min and max range of workers |
| Driver node type | guzzle.spark.driver_node_type_id | - | Define node type for driver node |
| Worker node type | guzzle.spark.node_type_id | - | Define node type for worker node |
| spark config | guzzle.spark.spark_conf | - | This is parameters is mainly used adding spark properties |
| Number of workers | guzzle.spark.workers.num_workers | - | Define number of worker nodes are required for job execution. |
| Autoscale min workers | guzzle.spark.workers.autoscale.min_workers | - | Define number of minimum workers that are required for workload. |
| Autoscale max workers | guzzle.spark.workers.autoscale.max_workers | - | Define number of maximum workers that are required for workload. |
driver_node type worker_node type override spark config workers
Synapse spark#
| Parameter | Parameter Name | Default Value | Description |
|---|---|---|---|
| Number of executors | guzzle.spark.num_executors | 1 | You can define number of execute required for your spark application |
| Driver memory | guzzle.spark.driver_memory | 1gb | Define driver node memory |
| Driver cores | guzzle.spark.driver_cores | 1 | Define drive cores |
| Executor memory | guzzle.spark.executor_memory | 1gb | Define memory for your execute node |
| Executor Core | guzzle.spark.executor_cores | 1 | Define number of drives |
| spark config | guzzle.spark.spark_conf | - | This is parameters is mainly used adding spark properties |
AWS Glue#
| Parameter | Parameter Name | Default Value | Description |
|---|---|---|---|
| Number of executors | guzzle.spark.num_executors | 1 | Define number of executor your spark job will use to execute workloads |
AWS EMR#
| Parameter | Parameter Name | Default Value | Description |
|---|---|---|---|
| Number of executors | guzzle.spark.num_executors | - | You can define number of execute required for your spark application |
| Driver memory | guzzle.spark.driver_memory | - | Define driver node memory |
| Driver cores | guzzle.spark.driver_cores | - | Define drive cores |
| Executor memory | guzzle.spark.executor_memory | - | Define memory for your execute node |
| Executor Core | guzzle.spark.executor_cores | - | Define number of drives |
| spark config | guzzle.spark.spark_conf | - | This is parameters is mainly used adding spark properties |
AWS EMR Serverless#
| Parameter | Parameter Name | Default Value | Description |
|---|---|---|---|
| Number of executors | guzzle.spark.num_executors | - | You can define number of execute required for your spark application |
| Driver memory | guzzle.spark.driver_memory | - | Define driver node memory |
| Driver cores | guzzle.spark.driver_cores | - | Define drive cores |
| Executor memory | guzzle.spark.executor_memory | - | Define memory for your execute node |
| Executor Core | guzzle.spark.executor_cores | - | Define number of drives |
| spark config | guzzle.spark.spark_conf | - | This is parameters is mainly used adding spark properties |
- Please check this excel file for more details on spark parameters - Guzzle Spark Parameters.