Schema Derivation Strategies
Guzzle provides five schema derivation strategies. Using these strategies Guzzle will validate the data type and will also create an effective schema based on that data will be written in the target and reject table. The schema derivation strategies include:
- Source
- Inherit source data type and do not apply validation
- Target
- Inherit target data type and do not apply validation
- Do not inherit schema from source or target
Users can select schema derivation strategy from Inherit columns and datatype property under Additional settings dropdown menu in the validation and transformation section.
In this article, we will discuss these strategies with examples
Source#
- If schema derivation strategy is source then, columns and data types will be inherited from the source files/table and, validation of data types will be performed based on source data types.
- If the user does not specify the column name in the transformation and validation section then validation for that column will be performed and if the user specifies the source's column name in the transformation and validation section then the validation will be performed based on validate data type checkbox.
- Additionally, an effective schema will be created using
- Source columns and their respective data types.
- Columns and data types are specified in the validation and transformation section of the ingestion job.
- And this effective schema will be used to create a table if an auto-create table checkbox is checked in the target section and in the reject section.
Example#
In source, a datastore is a file and format is delimited, and the file pattern includes two files that are file1.csv and file2.csv. And infer schema checkbox is checked in the source section. In target, the datastore is the delta table and the auto-create table checkbox is checked and the name of table is demo_schema_derivation.
The source data are like this
- In the validation and transformation section, we have defined
- A new column full_name is doing concatenation of name column and "_new" string. Since the full_name column does not exist in the source data, and we have provided data type value in the validation and transformation section so, Guzzle will respect that data type value and take that data type for the defined column. If the user does not provide the value of the data type then Guzzle will take string as a data type value.
- name column but a validate data type checkbox is unchecked, and also we haven't defined any data type so, Guzzle will not validate this column's data and the data type for this column will be inherited from the source as the name column is present in the source.
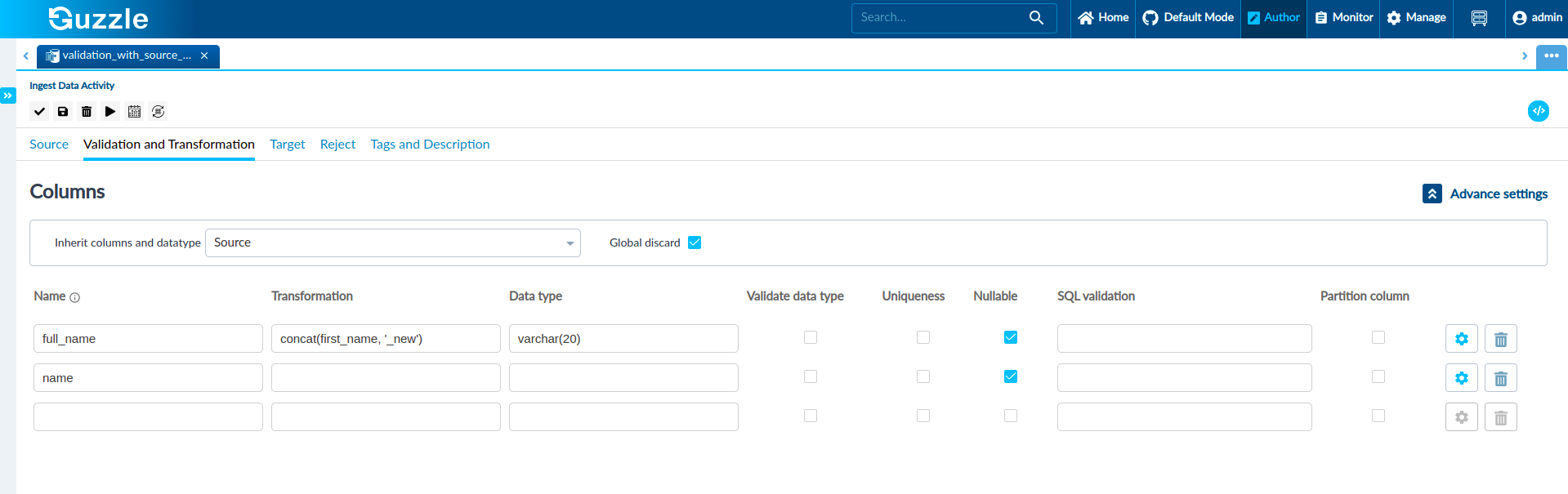
As shown in the figure that we have defined the data type for full_name column varchar(20) so, Guzzle will take this data type for the effective schema.
While running the ingestion job Guzzle will create the target table using the below query and as schema derivation strategy is the source so, it will validate data of source column like datatype for id is an integer so, data which are successfully validated will be stored in the target table and those which are invalid will be stored in reject table/file.
- After a successful run of this job target table contains the following data:
- Here, the data with id=id_1004 is discarded because the data is in string and the data type of id column is an integer. So, Guzzle will store this data in the reject section.
Inherit source data type and do not apply validation#
- If the schema derivation strategy is Inherit source data type and do not apply validation then, columns and data types will be inherited from the source files/table, but the validation of data types will not be performed automatically. This will be based on the validation and transformation section.
- If the user does not specify the column name in the transformation and validation section then validation for that column will not be performed and if the user specifies the source's column name in the transformation and validation section then the validation will be performed based on validate data type checkbox.
- Additionally, an effective schema will be created using
- Source columns and their respective data types.
- Columns and data types are specified in the validation and transformation section of the ingestion job.
- And this effective schema will be used to create a table if an auto-create table checkbox is checked in the target section and in the reject section.
Example#
In source, a datastore is a file and format is delimited, and the file pattern includes two files that are file1.csv and file2.csv. And infer schema checkbox is checked in the source section. In target, the datastore is the delta table and the auto-create table checkbox is checked and the name of the table is demo_schema_derivation.
The source data are like this
- In the validation and transformation section, we have defined
- A new column full_name is doing concatenation of name column and "_new" string. Since the full_name column does not exist in the source data, and we have provided data type value in the validation and transformation section so, Guzzle will respect that data type value and take that data type for the defined column. If the user does not provide the value of the data type then Guzzle will take string as a data type value.
- name column but a validate data type checkbox is unchecked, and also we haven't defined any data type so, Guzzle will not validate this column's data and the data type for this column will be inherited from the source as the name column is present in the source.
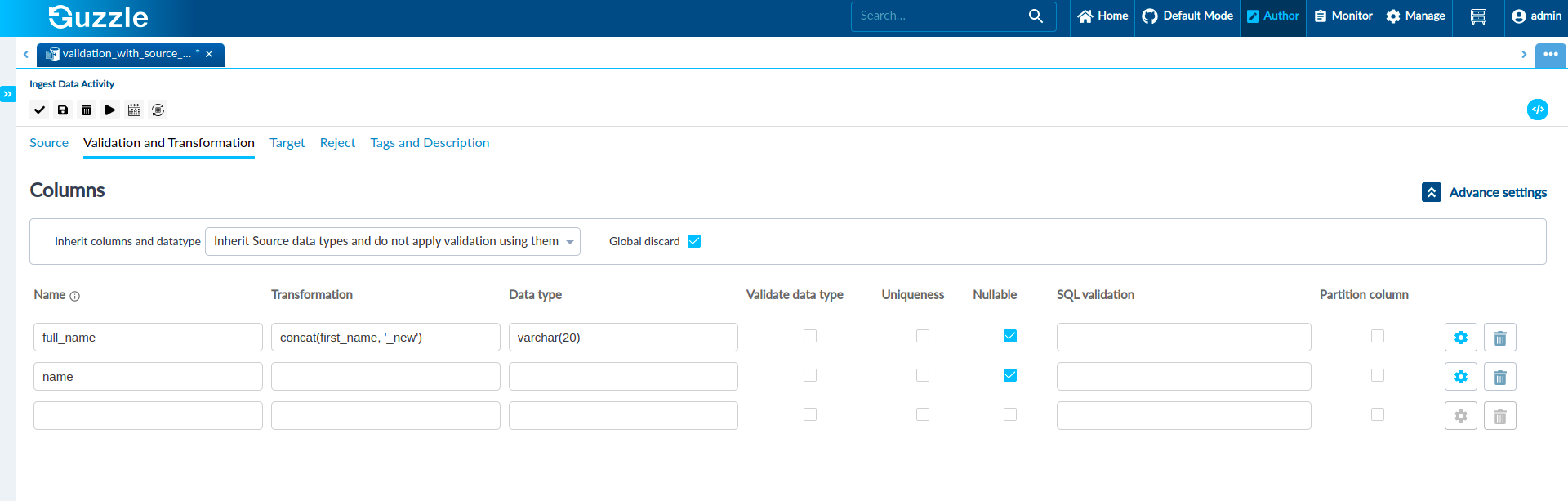
As shown in the figure that we have defined the data type for full_name column varchar(20) so, Guzzle will take this data type for the effective schema.
While running the ingestion job Guzzle will create the target table using the below query and as schema derivation strategy is the Inherit source data type and do not apply validation so, it will not do direct validation of the source column's data. So, Guzzle will take the help of the validation and transformation section on whether to validate or not.
If the user wants to validate the data of the id column then the user has to define the id column in the transformation and validation section with the checked validate data type checkbox.
And the data that are successfully validated will be stored in the target table and those which are invalid will be stored in the reject table/file.
- After a successful run of this job target table contains the following data:
- Here, id column is not defined in the validation and transformation section so, Guzzle will not validate the data. So, the data with id=id_1004 is not discarded, and this data is stored in the target table with id value NULL as shown in the above table.
Target#
note
If schema derivation strategy is target then auto-create table checkbox for target section must be unchecked, and target table will be there in the database.
- If schema derivation strategy is target then, columns and data types will be inherited from the target files/table and, validation of data types will be performed based on target data types.
- If the user does not specify the column name in the transformation and validation section then validation for that column will be performed and if the user specifies the target's column name in the transformation and validation section then the validation will be performed based on validate data type checkbox.
- Additionally, an effective schema will be created using
- Target columns and their respective data types.
- Columns and data types are specified in the validation and transformation section of the ingestion job.
- And this effective schema will be used to create a table if an auto-create table checkbox is checked in the reject section.
Example#
In source, a datastore is a file and format is delimited, and the file pattern includes two files that are file1.csv and file2.csv. And infer schema checkbox is checked in the source section. In target, the datastore is the delta table and the name of the table is demo_schema_derivation.
The source data are like this
- The target table data is
- In the validation and transformation section, we have defined
- A new column full_name is doing concatenation of name column and "_new" string. Since the full_name column does not exist in the target table, and we have provided data type value in the validation and transformation section so, Guzzle will respect that data type value and take that data type for the defined column. If the user does not provide the value of the data type then Guzzle will take string as a data type value.
- name column but a validate data type checkbox is unchecked, and also we haven't defined any data type so, Guzzle will not validate this column's data and the data type for this column will be inherited from the target as the name column is present in the target.
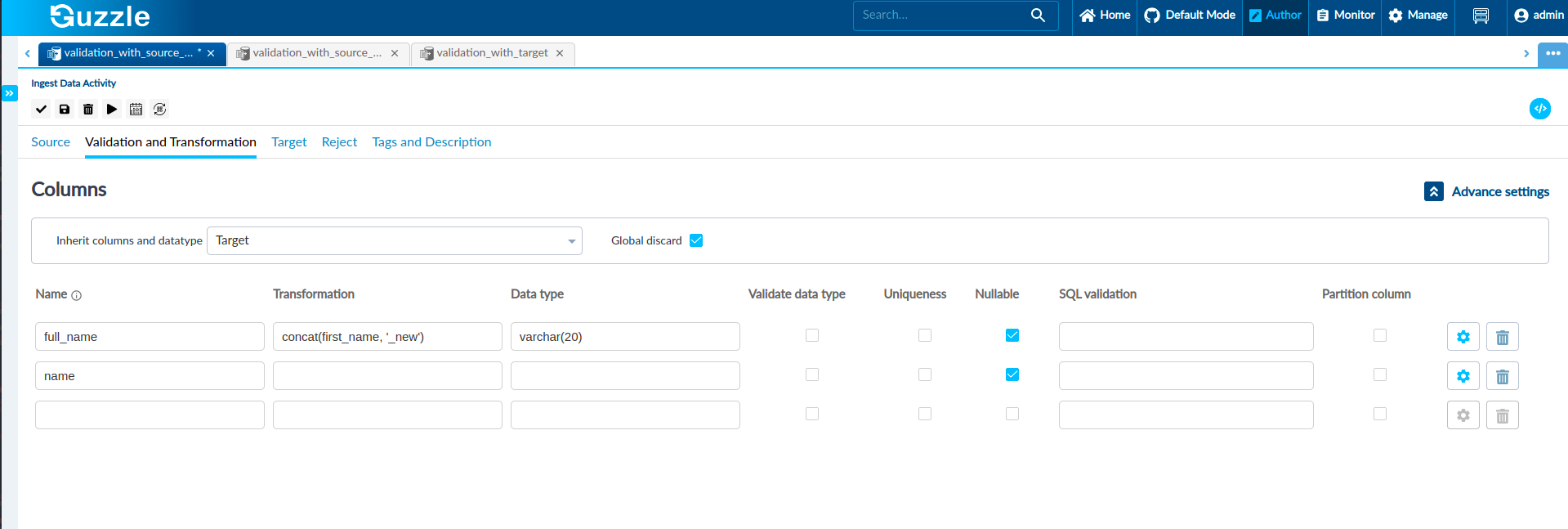
As shown in the figure that we have defined the data type for full_name column varchar(20) so, Guzzle will take this data type for the effective schema but as the target table does not have the full_name column, the data for this column will be ignored.
While running the ingestion job, as schema derivation strategy is the target, Guzzle will validate the data of source column with target data type like datatype for id is an integer so, data which are successfully validated will be stored in the target table and those which are invalid will be stored in reject table/file.
After a successful run of this job target table contains the following data:
- Here, the data with id=id_1004 is discarded because the data is in string and the data type of id column in target table is an integer. So, Guzzle will store this data in the reject section.
Inherit target data types and do not apply validation#
note
If schema derivation strategy is Inherit target data types and do not apply validation then auto-create table checkbox for target section must be unchecked, and target table will be there in the database.
- If the schema derivation strategy is Inherit target data types and do not apply validation then, columns and data types will be inherited from the target files/table and, the validation of data types will not be performed automatically. This will be based on the validation and transformation section.
- If the user does not specify the column name in the transformation and validation section then validation for that column will not be performed and if the user specifies the target's column name in the transformation and validation section then the validation will be performed based on validate data type checkbox.
- Additionally, an effective schema will be created using
- Target columns and their respective data types.
- Columns and data types specified in the validation and transformation section of the ingestion job.
- And this effective schema will be used to create a table if an auto-create table checkbox is checked in the reject section.
Example#
In source, a datastore is a file and format is delimited, and the file pattern includes two files that are file1.csv and file2.csv. And infer schema checkbox is checked. In target, the datastore is the delta table and the name of the table is demo_schema_derivation.
The source data are like this
- The target table data is
- In the validation and transformation section, we have defined
- A new column full_name is doing concatenation of name column and "_new" string. Since the full_name column does not exist in the target table, and we have provided data type value in the validation and transformation section so, Guzzle will respect that data type value and take that data type for the defined column. If the user does not provide the value of the data type then Guzzle will take string as a data type value.
- name column but a validate data type checkbox is unchecked, and also we haven't defined any data type so, Guzzle will not validate this column's data and the data type for this column will be inherited from the target as the name column is present in the target.
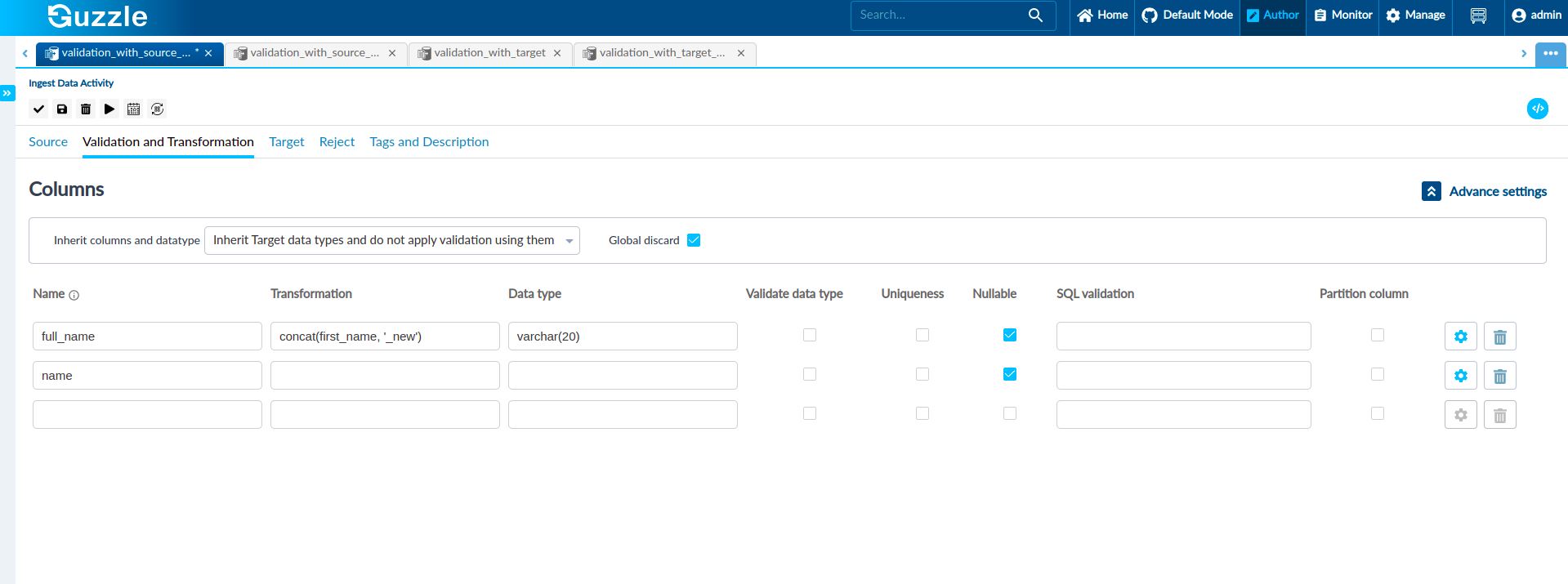
As shown in the figure that we have defined the data type for full_name column varchar(20) so, Guzzle will take this data type for the effective schema but as the target table does not have the full_name column, the data for this column will be ignored.
While running the ingestion job, as schema derivation strategy is the Inherit target data types and do not apply validation, Guzzle will not do direct validation of the source column's data with the target column's data type. So, Guzzle will take the help of the validation and transformation section on whether to validate or not.
And the data that are successfully validated will be stored in the target table and those which are invalid will be stored in the reject table/file.
After a successful run of this job target table contains the following data:
- Here, id column is not defined in the validation and transformation section so, Guzzle will not validate the data for that column. So, the data with id=id_1004 is not discarded, and this data is stored in the target table with id value NULL as shown in the above table.
Do not inherit schema from source or target#
- If the schema derivation strategy is Do not inherit schema from source or target then, columns and data types will be inherited from the transformation and validation section and, the validation of data types will be performed based on the validate data type checkbox. If the checkbox is checked then validation of that column will be performed, if unchecked then validation will not be performed.
- Additionally, an effective schema will be created using
- columns and data types specified in the validation and transformation section of the ingestion job.
- And this effective schema will be used to create a table if an auto-create table checkbox is checked in the target section and in the reject section.
Example#
In source, a datastore is a file and format is delimited, and the file pattern includes two files that are file1.csv and file2.csv. And infer schema checkbox is checked. In target, the datastore is the delta table and the auto-create table checkbox is checked and the name of table is demo_schema_derivation.
The source data are like this
- In the validation and transformation section, we have defined
- A new column full_name is doing concatenation of name column and "_new" string. Since the full_name column does not exist in the target table, and we have provided data type value in the validation and transformation section so, Guzzle will respect that data type value and take that data type for the defined column. If the user does not provide the value of the data type then Guzzle will take string as a data type value.
- name column but a validate data type checkbox is unchecked, and also we haven't defined any data type so, Guzzle will not validate this column's data and the data type for this column will be string as there is no data type defined.
- id column with data type value integer and validate data type checkbox is checked.
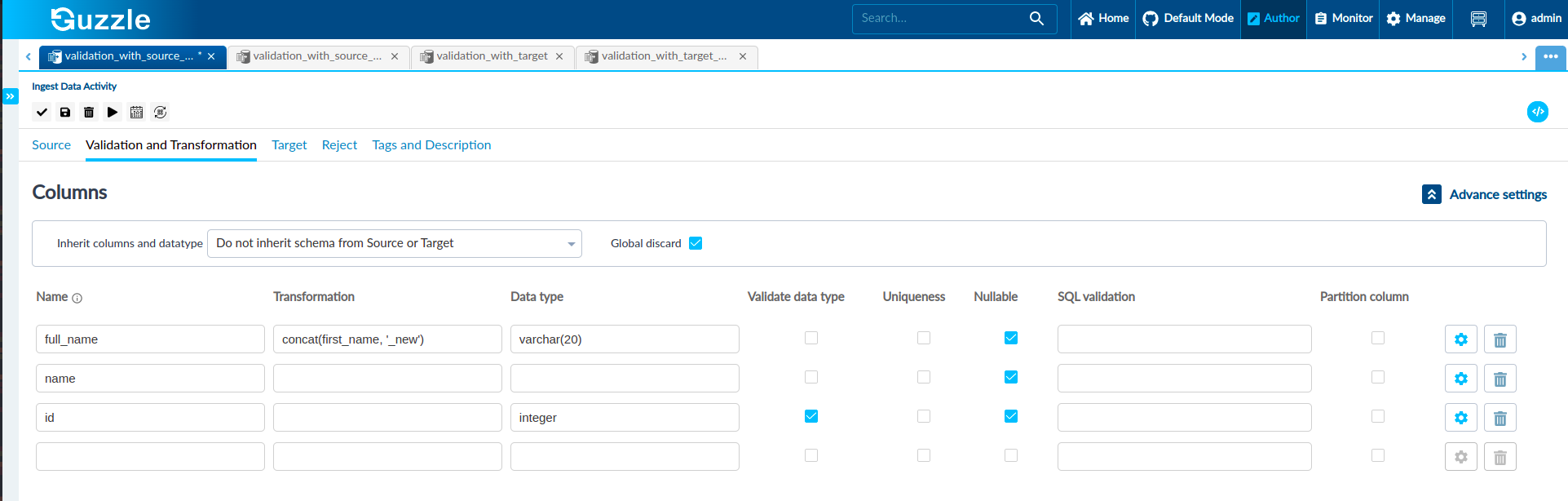
As shown in the figure, we have defined the data type for full_name column varchar(20), for id column is integer and for name column nothing so, Guzzle will take string data type and, Guzzle will take these columns and data type for the effective schema.
While running the ingestion job Guzzle will create the target table using the below query, as the schema derivation strategy is the Do not inherit schema from source or target, it will take the help of the validation and transformation section whether to validate or not.
And the data that are successfully validated will be stored in the target table and those which are invalid will be stored in the reject table/file.
After a successful run of this job target table contains the following data:
- Here, id column is defined in the validation and transformation section and validate data type checkbox is checked so, Guzzle will validate the data for that column. So, the data with id=id_1004 is discarded, and this data is stored in the reject section.